








 Custom services
Custom services
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
PermalinkINTRODUCCIÓN
Contar con las opiniones, actitudes y preferencias de los usuarios es uno de los elementos esenciales para una adecuada gestión de la calidad de los servicios deportivos. De este modo, el interés por los métodos de evaluación de las percepciones del consumidor en gestión deportiva es creciente (ej. Hernández-Mendo, Morales-Sánchez y González-Ruiz, 2012, Morales-Sánchez, Hernández-Mendo y Blanco, 2009; Morales-Sánchez, Pérez-López, Morquecho-Sánchez y Hernández-Mendo, 2016, Theodorakis, 2014). Entre esos diferentes métodos de evaluación se encuentra el análisis de importancia-valoración, conocido también como IPA (Importance-Performance Analysis).
El IPA es una herramienta cada vez más empleada en el ámbito de las Ciencias del Deporte (ej. Arias-Ramos, Serrano-Gómez y García-García, 2016; Chard, MacLean y Faught, 2013; Huang, Ye y Kao, 2015; Rial, Rial, Valera y Rial, 2008; Serrano-Gómez, Rial, Sarmento y Carvalho, 2014; Zamorano-Solís y García-Fernández, J., 2018). Introducida por Martilla y James (1977), la sencillez de su implementación y la posibilidad de obtener una representación gráfica muy intuitiva sobre cómo priorizar recursos, hace que esta metodología sea muy atractiva para su empleo en la gestión deportiva.
Básicamente, el método consiste en proponer una serie de atributos relacionados con el servicio deportivo, y que los participantes en el estudio indiquen su importancia y su valoración. Es decir, se obtienen dos variables asignadas a cada atributo por las cuales los usuarios emiten un juicio subjetivo sobre cómo de relevantes son para ellos esos atributos y qué puntuación le otorgan. Así, teóricamente, se obtiene un dibujo de cuáles son las preferencias y percepciones de los participantes, el cual puede representarse esquemáticamente en una figura bidimensional, dividida normalmente en cuatro cuadrantes en el que se muestran la puntuación obtenida, y su catalogación como aspectos sobre los que la gestión debe concentrarse, mantener el nivel, son de baja prioridad, o sugieren un posible derroche de recursos (ver Ábalo, Varela y Rial, 2006).
Además, se suelen calcular las discrepancias entre la valoración y la importancia de cada atributo para evaluar si necesita mejorar, y luego se evalúa esa discrepancia en función de la importancia que tiene. Es decir, frente a dos atributos con la misma discrepancia la gestión deberá priorizar recursos para elevar la valoración sobre el que tenga más importancia. Del mismo modo, las discrepancias obtenidas pueden compararse entre subpoblaciones, por ejemplo, entre datos obtenidos de instalaciones públicas frente a privadas (ver Arias-Ramos, et al., 2016), o incluso comparar la valoración de atributos de importancia similar, multiplicando esa importancia por la valoración obtenida.
Sin embargo, la utilidad de esta técnica descansa sobre el adecuado manejo de los siguientes aspectos: (1) La consideración del error de medición de cada punto situado en el gráfico; (2) La propagación de errores cuando se calcula la discrepancia entre la importancia y la valoración de cada atributo; (3) La propagación de errores cuando se emplea cualquier otra función de las dos variables originales: importancia y valoración.
Dado que ninguna de los mencionados aspectos se ha considerado en la literatura publicada en Ciencias del Deporte, el objetivo de esta investigación es explicar cómo pueden tenerse en cuenta para mejorar sensiblemente los resultados reportados cuando se emplea esta metodología.
MATERIAL Y MÉTODOS
Especificación de las variables
Sean X e Y variables aleatorias que representan, respectivamente, la valoración y la importancia de M atributos de un servicio deportivo. Así, siendo (xij) e (yij) las realizaciones de las variables aleatorias para cada individuo i al evaluar la valoración e importancia de cada atributo j. Para una muestra de tamaño n, i varía desde 1 hasta n, mientras que la variación de j es de 1 hasta M.
El procedimiento habitual es computar el valor medio de cada atributo j 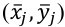 . Ese par, es representado gráficamente tomando la valoración xj. Ese par, es representado gráficamente tomando la valoración
. Ese par, es representado gráficamente tomando la valoración xj. Ese par, es representado gráficamente tomando la valoración 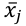 el eje de abcisas y la importancia 𝑦̅𝑗 el de ordenadas. Además, la discrepancia D, manifestada por
el eje de abcisas y la importancia 𝑦̅𝑗 el de ordenadas. Además, la discrepancia D, manifestada por 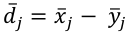 es calculada con el fin de evaluar, principalmente, qué atributos son los que presentan un mayor “gap” o divergencia entre su relevancia y la puntuación de los usuarios. Es común, como ocurre en Arias-Ramos et al. (2016), que esas discrepancias sean negativas, es decir, que la puntuación esté por debajo de la importancia, cuando ambas variables se miden en escalas comparables.
es calculada con el fin de evaluar, principalmente, qué atributos son los que presentan un mayor “gap” o divergencia entre su relevancia y la puntuación de los usuarios. Es común, como ocurre en Arias-Ramos et al. (2016), que esas discrepancias sean negativas, es decir, que la puntuación esté por debajo de la importancia, cuando ambas variables se miden en escalas comparables.
Asimismo, una nueva variable, a la que denominaremos H, puede construirse como multiplicación de la importancia y valoración de cada atributo: 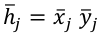 . De este modo, se pueden comparar las puntuaciones de dos atributos diferentes, y además del mismo atributo en diferentes subpoblaciones de N (por ejemplo, la subpoblación a y la b), a través de las submuestras na y nb. En consecuencia,
. De este modo, se pueden comparar las puntuaciones de dos atributos diferentes, y además del mismo atributo en diferentes subpoblaciones de N (por ejemplo, la subpoblación a y la b), a través de las submuestras na y nb. En consecuencia, 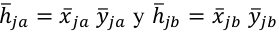 pueden compararse cuando
pueden compararse cuando 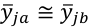 .
.
Error estadístico
Cada valor esperado calculado, sobre el conjunto de datos x0 tiene un error 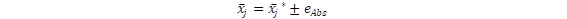 , siendo
, siendo 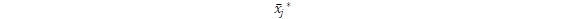 el valor poblacional (que suponemos un parámetro fijo), y eAbs el error absoluto de estimación. De este modo, se postula que
el valor poblacional (que suponemos un parámetro fijo), y eAbs el error absoluto de estimación. De este modo, se postula que 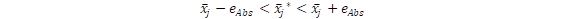 . Sin embargo, la aproximación estadística a las estimaciones de los errores nos indica que
. Sin embargo, la aproximación estadística a las estimaciones de los errores nos indica que 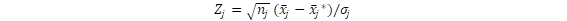 , donde
, donde 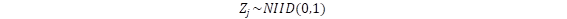 , y nj es el tamaño de la muestra para ese atributo y
, y nj es el tamaño de la muestra para ese atributo y 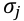 la varianza poblacional. NIID significa normal, independiente e idénticamente distribuida. A
la varianza poblacional. NIID significa normal, independiente e idénticamente distribuida. A 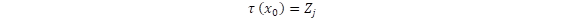 se le llama estadístico de contraste.
se le llama estadístico de contraste.
Como casi siempre desconocemos esa varianza poblacional, la estimamos a través de la varianza muestral Sj, con lo que el estadístico resultante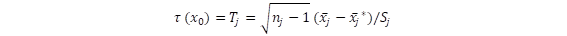 sigue una distribución t-Student. Para muestras grandes Zj y Tj convergen.
sigue una distribución t-Student. Para muestras grandes Zj y Tj convergen.
Para simplificar, y considerando muestras los suficientemente grandes, usaremos el valor Z como ilustración, lo que dado un tamaño del test α=0.05 previamente definido (Spanos, 2014), se deriva la tan conocida expresión: 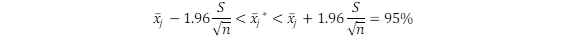 . Remitimos a cualquier manual de estadística para un mayor detalle (ej. Casas, 1997).
. Remitimos a cualquier manual de estadística para un mayor detalle (ej. Casas, 1997).
Así, el error absoluto de estimación va a depender de la confianza de la misma, y del error de la media: 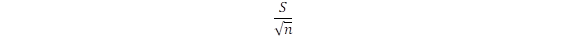 . Por tanto, y siguiendo con el ejemplo anterior:
. Por tanto, y siguiendo con el ejemplo anterior: 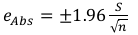
Error en cada punto del gráfico
Rápidamente se intuye que mostrar el par en el gráfico de importancia-valoración es poco informativo si no se indican sus respectivos errores. Así, una práctica más correcta sería incluir en la representación las barras de error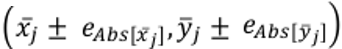 . Esas barras de error horizontales y verticales proporcionarían una información mucho más rica sobre la existencia de diferencia entre atributos, y su posible solapamiento entre dos o más cuadrantes del diagrama.
. Esas barras de error horizontales y verticales proporcionarían una información mucho más rica sobre la existencia de diferencia entre atributos, y su posible solapamiento entre dos o más cuadrantes del diagrama.
Si esto no se hace, los autores estarán realizando interpretaciones sobre los datos sin tener en cuenta su error asociado, es decir, podrían llegar potencialmente a la misma conclusión independientemente de que la muestra fuera de 30 o de 3000, que la dispersión de la media fuera baja o alta, o que el nivel de confianza fuera del 90% o del 99%.
Propagación de errores
Los errores cometidos en la estimación de la media de cada variable se propagan cuando se combinan en una función de esas variables. Sea g = f(xj,yj) una función que depende de la valoración y de la importancia de cada atributo. Mediante una serie de Taylor se puede aproximar esa función en el entorno del valor esperado de ambas variables. De manera general:
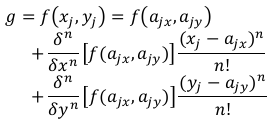
Si, como hemos indicado, se desarrolla la función en el entorno del promedio de ambas variables, entonces: 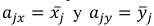 , por lo que el primer término de la serie (n=1, es decir, considerando sólo la primera derivada) sería:
, por lo que el primer término de la serie (n=1, es decir, considerando sólo la primera derivada) sería:
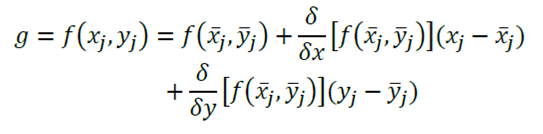
Dado que se puede demostrar que 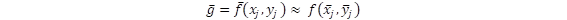 a medida que la muestra crece (ver Ku, 1966), entonces se puede definir w como:
a medida que la muestra crece (ver Ku, 1966), entonces se puede definir w como:
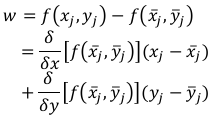
Por tanto:
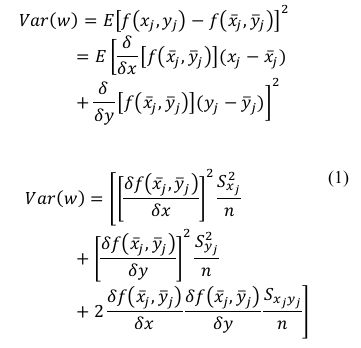
De este modo, y dado que el error absoluto de la función: 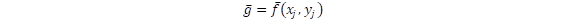 es:
es:
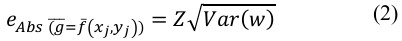
Cuando (xj,yj) son independientes, entonces su covarianza es nula, por lo que al final podemos llegar a una expresión simplificada de la propagación de errores:
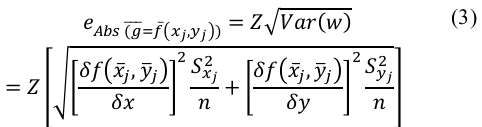
APLICACIÓN A UN CASO SIMULADO
Generación de datos
Para ilustrar el empleo de las ecuaciones anteriores, vamos a simular los datos de un centro deportivo en el que se valoran la importancia y valoración de 3 atributos. Para ello, hemos generado los datos de x1,x2,x3,y1,y2,y3 provenientes de una distribución beta (a,b), con los siguientes parámetros y estadísticos (Tabla 1).
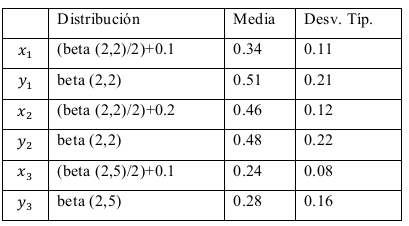
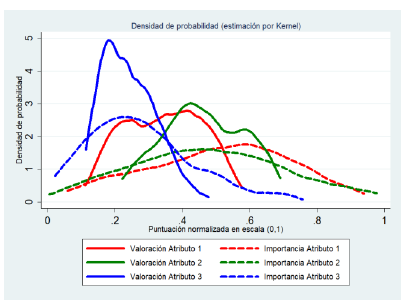
Los datos fueron generados con Stata 13.0 para un total de 200 observaciones, y la idea era obtener un dibujo de distribuciones diverso donde hubiera una discrepancia entre la valoración y la importancia de cada atributo. Gráficamente, la Figura 1 ayuda a entender las características de los datos, tras estimar sus distribuciones usando Kernel. El empleo de la distribución beta es simplemente una manera de generar datos acotados en el intervalo (0,1), que pueden representar perfectamente cualquier normalización de una escala Likert o similar, tal y como describen Cohen, Cohen, Aiken y West (1999).
Estimación del error y representación
Los errores absolutos se estiman empleando el procedimiento descrito en el apartado 2.2., es decir, empleando la aproximación Normal y al 95% de confianza. Obviamente, otras aproximaciones más sofisticadas pueden también implementarse, aunque quedan lejos del objetivo de este artículo. La Tabla 2 muestra los resultados.

Cada par de valores se representa por un punto, mientras que las barras de error 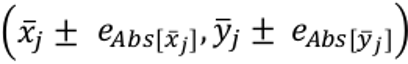 se representan con líneas, formando una cruz, tal y como aparece en la Figura 2.
se representan con líneas, formando una cruz, tal y como aparece en la Figura 2.
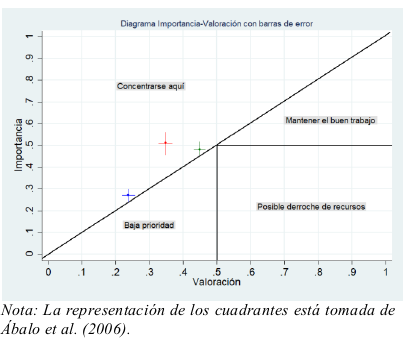
Como puede observarse, la representación del error refleja mucho mejor la incertidumbre de los datos, y para los casos del Atributo 2 (color verde) y Atributo 3 (color azul) un leve incremento del error (por ejemplo, al usar una muestra menor) hubiera supuesto el solapamiento con la región de “baja prioridad”, lo que llevaría a interpretar los resultados con una óptica ligeramente diferente.
Cómputo de las discrepancias
Tal y como hemos comentado, es habitual el cómputo de las discrepancias para cada atributo, en aras de conocer las posibles divergencias negativas entre la valoración y la importancia. Una discrepancia negativa significa que el atributo es más importante de lo que se ha valorado, por lo que puede ser un indicador de una atención especial.
De nuevo es necesario reportar los errores de esa discrepancia, algo inusual en la investigación empírica, pero totalmente relevante para interpretar los resultados correctamente. Como 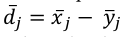 , entonces esa discrepancia es una función de dos variables aleatorias, y se deben computar los errores usando las expresiones (1) y (2). En la Tabla 3 se calculan de manera ilustrativa cada uno de los términos.
, entonces esa discrepancia es una función de dos variables aleatorias, y se deben computar los errores usando las expresiones (1) y (2). En la Tabla 3 se calculan de manera ilustrativa cada uno de los términos.

Obsérvese que el procedimiento descrito para hallar el error absoluto de la discrepancia ofrece el mismo resultado que realizar una prueba t para muestras pareadas. Sin embargo, la ecuación (1) es válida para hallar cualquier función de la importancia y la valoración, como puede ser, por ejemplo, el producto entre ambas variables 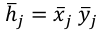 . Así, la manera hallar el error de
. Así, la manera hallar el error de  requiere exactamente del mismo procedimiento, sólo que ahora las derivadas parciales no resultan en la unidad, sino en las variables medias del atributo.
requiere exactamente del mismo procedimiento, sólo que ahora las derivadas parciales no resultan en la unidad, sino en las variables medias del atributo.
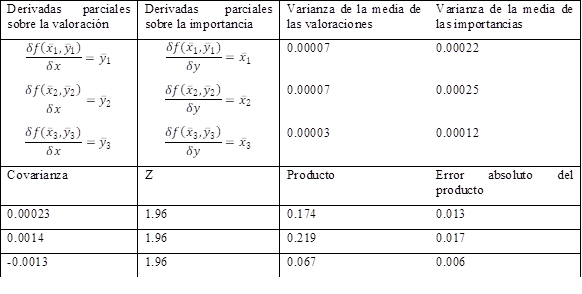
Esto hace que se puedan comparar dos atributos que se han evaluado con importancia similar, pero con diferente valoración, como los atributos 1 y 2. Así: 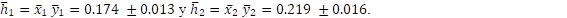 . Como puede comprobarse los intervalos de error no se solapan, por lo que ambos productos pueden considerarse diferentes.
. Como puede comprobarse los intervalos de error no se solapan, por lo que ambos productos pueden considerarse diferentes.
DISCUSIÓN
En esta breve nota hemos descrito de manera sencilla cómo pueden mejorarse los análisis y la presentación de resultados en los estudios que empleen la metodología del análisis importancia-valoración. Dado que esta metodología es fácilmente ejecutable y provee resultados intuitivos, su aplicación para la gestión deportiva es muy atractiva. Sin embargo, ignorar los elementos descritos en este artículo hace que los estudios puedan tener limitaciones importantes que cuestionen sus conclusiones.
La consideración de los errores de medición es de vital relevancia en las variables “importancia” y “valoración”, y más teniendo en cuenta que su medición se suele realizar en escalas de intervalo, y que éstas suelen ser incluso del mismo rango, lo que puede hacer aparecer, además, problemas de sesgo de método común (Podsakoff, MacKenzie y Podsakoff, 2012). Esto podría incrementar artificialmente la covarianza entre ambas variables y, de esta forma, perturbar el cálculo del error propagado. Para minimizar este posible problema los investigadores podrían emplear escalas diferentes de medición para la importancia y la valoración.
Eskildsen y Kristensen (2006) mostraron que las medidas de importancia y valoración no eran independientes, e indicaron que esto podría ser un problema para la validez de los resultados. Sin embargo, realmente cuando se propagan los errores usando el método descrito en esta investigación, se tiene en cuenta la covarianza entre ambas variables, por lo que esa carencia de independencia no influye en la cuantificación final del error.
El desarrollo de la propagación de errores puede ampliarse consultando a Goodman (1960), y también puede enfocarse centrándose en el cómputo del error relativo, en lugar del error absoluto. Esto es especialmente indicado para productos que no se miden con las mismas unidades o en rangos muy dispares. Para el caso de las escalas cuantitativas empleadas comúnmente en Ciencias Sociales, esto es menos importante porque todas se pueden normalizar a un intervalo (0,1), tal y como Cohen et al. (1998) explican. No obstante, en esa normalización es recomendable que las escalas tengan una longitud similar, para que la precisión de los instrumentos sea también parecida.
Los análisis de importancia-valoración pueden realizarse en submuestras, como por ejemplo para distinguir entre instalaciones públicas y privadas (ver Arias-Ramos et al., 2016). Para comparar las discrepancias entre ambas submuestras en cada atributo simplemente hay que emplear de nuevo la propagación de errores descrita en la ecuación (3), es decir, para muestras independientes. De este modo, se hallarían primero las discrepancias y los errores para cada submuestra empleando las ecuaciones (1) y (2), y luego se computarían la diferencia entre ambas discrepancias con la propagación de errores expresada en la ecuación (3).
El procedimiento descrito en este artículo debe hacerse extensible más allá del ámbito de las Ciencias del Deporte. De hecho, el IPA se ha empleado, entre otros, en contextos tan dispares como la evaluación de la calidad universitaria (Rial, Grobas, Braña y Varela, 2012), servicios públicos digitales gubernamentales (Wong, Hideki y George, 2011), hospitales (Yavas y Shemwell, 2001) o turismo (Ziegler, Dearden y Rollins, 2012). Aunque es cierto que se han discutido diferentes aproximaciones para gestionar las limitaciones del IPA en relación a la ubicación de los ejes y selección de los atributos (ver Rial et al., 2012), se necesita también calcular y reportar correctamente los errores de medición, tal y como hemos explicado en esta investigación.
Futuros trabajos podrían asimismo profundizar en aproximaciones de lógica borrosa, como la realizada por Wang, Tai, Chen, y Yang (2010). Sin embargo, aunque se tenga en cuenta la borrosidad de los números asignados a las etiquetas lingüísticas, si luego esos números borrosos se convierten en números concretos, los problemas de cómputo de error estadístico y propagación de esos errores persisten en el reporte del diagrama final.
CONCLUSIONES
El análisis de importancia-valoración puede ser una herramienta muy útil para la gestión de servicios deportivos, pero necesita ser enfocado desde una perspectiva más completa a la hora de calcular y reportar los errores de medición. En esta investigación hemos dado las indicaciones precisas para ayudar a mejorar esta situación, fundamentalmente a través del cálculo de las barras de error y la propagación cuadrática de errores para cualquier función que se construya empleando las variables originales: importancia y valoración.