










 Servicios personalizados
Servicios personalizados
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares en
SciELO
Similares en
SciELO  Similares en Google
Similares en Google 
 Permalink
PermalinkINTRODUCCIÓN
La identificación de las líneas de investigación y sus interconexiones, a partir de la información contenida en las bases de datos, es esencial para comprender la estructura de conocimiento de un dominio científico. En este sentido, las líneas de investigación son asimilables a los grupos temáticos que componen un área de conocimiento. La justificación de este trabajo fue comprender mejor la estructura de conocimiento del dominio científico de la salud pública, analizando los artículos de investigación publicados en la Revista Española e Salud Pública (RESP).
En relación con lo anterior, uno de los retos de la Bibliometría y la Cienciometría es estudiar la producción científica en un dominio científico con el fin de medir y analizarla. Con esta finalidad se han desarrollado múltiples métodos dirigidos a medir los aspectos cuantitativos y cualitativos de la literatura en un campo científico. La producción científica indexada en las bases de datos hace posible que se puedan procesar de forma automática las diversas unidades de información contenidas en los registros bibliográficos (tales como, citas, autores, palabras-clave, o términos contenidos en los títulos y resúmenes). El procesamiento de estas unidades se usa en la investigación bibliométrica para identificar, entre otros aspectos, grupos de documentos con patrones similares que sirven, a su vez, para analizar la estructura, el desarrollo y la evolución de un dominio científico1. En el dominio de la salud pública en España son diversas las aportaciones bibliométricas realizadas2,3,4,5,6.
Por su parte, los mapas bibliométricos, mapas de la ciencia o cienciogramas, son una representación espacial de un dominio científico, que permiten delimitar diferentes áreas de investigación, con la finalidad de analizar su estructura conceptual y la dinámica de su evolución7. Los mapas bibliométricos ofrecen una mejor comprensión de la estructura de un dominio científico a través de la representación gráfica de las diferentes unidades de análisis y sus relaciones8. Para la generación de los mapas de la ciencia se aplica un tipo de indicadores bibliométricos, denominados indicadores relacionales9,10. Esto es, la mayoría de los mapas de la ciencia se construyen básicamente por el principio de las relaciones de co-ocurrencia, o aparición conjunta, de dos unidades de información en un documento. Así, cuanto más cerca se encuentren dos elementos relacionados entre sí más cerca se localizarán en el mapa.
Siguiendo con lo anterior, a partir del establecimiento de relaciones de co-ocurrencia entre las correspondientes unidades de análisis, se han desarrollado diversas metodologías11 entre las que se destacan: a) análisis de co-citación, a través del cual se mide la similitud, o similaridad, entre documentos basada en las referencias bibliográficas de los mismos, se dirige fundamentalmente al estudio de los aspectos de la estructura intelectual o base de conocimiento de un área de investigación12,13; b) análisis de co-autoría, por medio del cual se mide la similaridad documental basada en las relaciones de co-autoría y de colaboración institucional, se dirige al estudio de los aspectos sociales y la dimensión internacional de un campo científico14; y c) análisis de co-palabras, co-word analysis, por medio del cual se mide la similaridad documental mediante el análisis de palabras, básicamente este método consiste en detectar las palabras (que representan conceptos de los documentos en un dominio científico) y relacionar los documentos en los que aparecen según su grado de co-ocurrencia. Este procedimiento es el que se dirige al estudio de la estructura temática, semántica, conceptual y cognitiva de un área de investigación15,16.
Una vez realizado el procesamiento de las correspondientes palabras se construyen matrices relacionales sobre las que se aplican algoritmos de agrupamiento, o clustering. Finalmente, las diferentes agrupaciones se representan en mapas bibliométricos, en los que las relaciones entre las diferentes unidades de análisis se visualizan básicamente de dos formas: a) mapas basados en gráficos, en los que las relaciones se establecen en forma de vínculos o enlaces gráficos17,18. Este tipo de representaciones puede dar lugar a mapas poco legibles, en los que no se visualizan bien las relaciones cuando se trata de redes con una gran densidad de enlaces; y b) mapas basados en la posición o distancia en los que las relaciones se representan como puntos cercanos en un espacio de una o dos dimensiones19,20 .
El objetivo de este trabajo fue identificar las principales líneas de investigación dentro del dominio de la salud pública en la Revista Española de Salud Pública durante el periodo 2006-2015.
MATERIAL Y MÉTODOS
Se visualizaron los temas de investigación, tratados en los trabajos científicos publicados en RESP durante el periodo 2006-2015. Se utilizó una metodología cuantitativa basada en el análisis de co-palabras y en la visualización de las relaciones entre palabras o términos a través de mapas bibliométricos bidimensionales. Con los mapas resultantes se realizó un análisis cualitativo para identificar la estructura temática y semántica del dominio científico que pretendimos examinar.
La metodología cuantitativa para la construcción de los mapas bibliométricos se dividió en diversas etapas21: i) recopilación de datos, ii) selección de las unidades de análisis, iii) cálculo de la frecuencia de co-ocurrencias e índice de similaridad entre las unidades de información, y iv) posicionamiento, y visualización de las correspondientes unidades de análisis en mapas bidimensionales. Para el procesamiento cuantitativo de los datos se utilizó el software VOSviewer22, una herramienta para la visualización de redes bibliométricas desarrollada en el Centre for Science and Technology Studies (CWTS).
Recogida de datos. El material de este estudio se extrajo de la base de datos multidisciplinar Social Sciences Citation Index (SSCI), disponible online a través de la Web of Science (WoS)23, un servicio integrado en ISI Web of Knowledge (Wok). La publicación RESP fue incluida dentro del SSCI en 2006, dentro de la categoría Public, Environmental and Occupational Health24. La estrategia de búsqueda empleada consistió en utilizar los términos Rev Esp Salud Pública en el campo 'Nombre de la publicación', Article en el campo 'Tipo de documento' limitada al período temporal de 2006-2015. Se seleccionaron solo artículos originales (frente a notas clínicas, revisiones, cartas científicas o editoriales) porque se consideró que este tipo de publicación es la que refleja de forma precisa los resultados probados de las investigaciones en el campo de la salud pública.
Unidades de análisis. A partir de los documentos recuperados se escogieron las palabras clave, o descriptores, con las que está indexada la producción científica biomédica de la publicación RESP en la base de datos SSCI. En dicha base de datos, los registros incluyen dos tipos de palabras clave: a) de autor, Author Keywords (AKW), proporcionadas por los propios autores; y b) KeyWords Plus (KW+), extraídas de forma automática por SSCI a partir de la frecuencia de aparición de las palabras en los títulos de las referencias de los artículos citados25. En este trabajo se seleccionaron las KW+ porque estas unidades de análisis, obtenidas de forma automática, reflejan mejor la dinámica de un campo científico por tratarse de términos actualizados, de mayor calidad y más específicos en comparación, con las palabras clave de los autores, o las procedentes de otros vocabularios controlados. Para que la muestra fuera representativa de los grupos temáticos, se seleccionaron solo las KW+ cuya frecuencia fuera ≥3 veces (esto es, las KW+ que ocurrieran o aparecieran al menos 3 veces en la producción científica recuperada).
Cálculo de la frecuencia de co-ocurrencia e índice de similaridad. Para la identificación y visualización de los grupos temáticos de RESP se calculó la frecuencia de ocurrencias y co-ocurrencias de las KW+. A continuación se construyó una matriz cuadrada de N por N elementos, o matriz de co-ocurrencias entre pares de KW+, que se cargó en la herramienta VOSviewer. Para el posicionamiento de las KW+ en el mapa, se utilizó la técnica VOS26, visualization of similarities, la cual construye una matriz de similaridad, a partir de la matriz de co-ocurrencia, utilizando como índice de similaridad para normalizar la red bibliométrica la medida conocida como Fuerza de Asociación (FA), Association Strength27. El índice de similaridad "fuerza de asociación" se basa en la normalización de los valores de co-ocurrencia y se aplica para que dichos valores representen de forma adecuada el corpus analizado y faciliten su agrupamiento, o clustering.
Posicionamiento y visualización de datos. La técnica VOS permite ejecutar un algoritmo de clustering28 para posicionar y clasificar las KW que serán mapeadas. El algoritmo de clustering incluye diferentes parámetros de resolución, según el valor que se proporcione para configurarlo, de tal forma que un menor parámetro de resolución implica una disminución paralela del número de clusters generados y un mayor parámetro de resolución implica un incremento paralelo del número de clústeres generados). Se ejecutaron varias pruebas introduciendo distintos valores en el parámetro de resolución del algoritmo, en las que se obtuvieron diferentes conjuntos de clusters. Después de analizar los resultados de diferentes pruebas de resolución, en base al algoritmo de clustering, se decidió aplicar un parámetro de resolución con valor 5 para la obtención de clusters temáticos homogéneos. Además, se consideró que, con independencia del parámetro de resolución del algoritmo, el tamaño mínimo de los clusters no fuera inferior a 6 KW+, garantizando de esta forma una serie de grupos temáticos con un mínimo de consistencia. Para la visualización de los datos se aplicaron mapas bibliométricos bidimensionales, en los que la representación de las relaciones entre las unidades de análisis se basa en la posición o distancia entre los nodos28. A su vez, con la herramienta VOSviewer se realizaron a su vez dos tipos de representaciones espaciales: 1) un mapa bibliométrico etiquetado que nos permitió obtener una visualización gráfica de las KW+ mediante nodos etiquetados y agrupaciones temáticas, o clusters; y 2) un mapa bibliométrico de densidad en el que cada nodo se representó por una escala de colores que revelaron la densidad de las relaciones entre las KW+ (el color rojo indicó la densidad más alta, los amarillos y verdes indicaron una densidad intermedia y el azul oscuro indicó la densidad más baja). Además, para interpretar el mapa de densidad se tuvoen cuenta, por un lado, el número de ítems posicionados en esa zona y, por otro, el peso de las KW+ en esa zona.
RESULTADOS
Se recuperó un total de 512 documentos correspondientes al período completo 2006-2015 (Tabla 1), de los cuales se obtuvieron un total de 176 KW+ con una frecuencia ≥3 (Tabla 2). Después de aplicar el algoritmo de clustering, con un parámetro de resolución con valor 5, se generaron 10 agrupaciones temáticas, en las que se reflejó el grado de similaridad de las KW+. Tras inspeccionar y verificar la homogeneidad semántica de las KW+ que conformaron cada cluster se proporcionó de forma manual un encabezamiento a cada grupo temático resultante. Las agrupaciones temáticas resultantes se visualizaron a través de un mapa bibliométrico etiquetado y un mapa bibliométrico de densidad.
Tabla 1 Número de artículos, correspondientes al período 2006-2015, recogidos en la base de datos Social Sciences Citation Index (SSCI)
| Año | Documentos |
|---|---|
| 2006 | 46 |
| 2007 | 45 |
| 2008 | 48 |
| 2009 | 66 |
| 2010 | 59 |
| 2011 | 55 |
| 2012 | 46 |
| 2013 | 51 |
| 2014 | 42 |
| 2015 | 54 |
| Total documentos | 512 |
Tabla 2 Muestra de las 30 KW+ con mayor número de frecuencias
| KW+ | Frecuencias |
|---|---|
| Salud | 50 |
| Población | 41 |
| España | 40 |
| Prevalencia | 30 |
| Mortalidad | 27 |
| Estados-Unidos | 23 |
| Atención | 21 |
| Enfermedad | 19 |
| Niños | 19 |
| Prevención | 19 |
| Riesgo | 19 |
| Adolescentes | 18 |
| Impacto | 18 |
| Factores de Riesgo | 16 |
| Mujer | 16 |
| Adultos | 14 |
| Atención Primaria | 14 |
| Meta-análisis | 13 |
| Porcentaje | 13 |
| Tendencias | 13 |
| Asociación | 13 |
| Virus | 12 |
| Gestión | 12 |
| Epidemiología | 12 |
| Directrices | 11 |
| Obesidad | 11 |
| Enfermedad Coronaria | 11 |
| Hombre | 10 |
| Calidad | 10 |
| Infección | 10 |
En el mapa bibliométrico etiquetado (Figura 1), el tamaño de los clusters estuvo determinado por diferentes factores, tales como número de KW+ dentro de los clústeres, frecuencia de ocurrencias de las KW+ y su peso o índice similaridad. Cada grupo o cluster se distinguió por un color aleatorio. En la Tabla 3 se indica el color del cluster temático correspondiente y las KW+ con mayor peso. Los clusters situados en el centro del mapa indicaron una alta interrelación de las KW+ que los conformaron, mientras que clusters situados en los márgenes o bordes del mapa indicaron una menor interrelación de las KW+. Por otro lado, el tamaño de las etiquetas de las KW+ fue proporcional a su frecuencia de aparición. Como resultado del mapa bibliométrico etiquetado se obtuvieron 10 clusters temáticos que definieron las principales corrientes de investigación en salud pública:
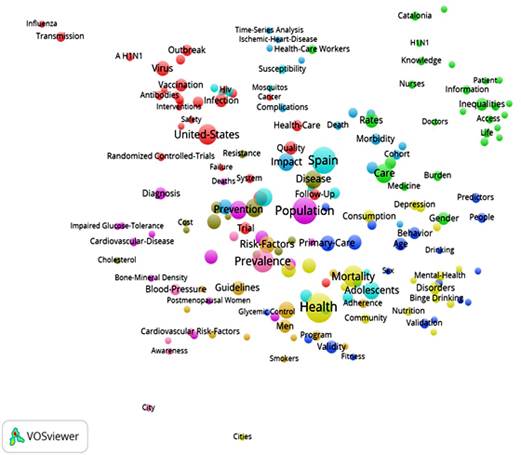
Figura 1 Mapa bibliométrico etiquetado, en el que se representaron las 176 KW+ analizadas (las etiquetas y el tamaño de los círculos reflejan el peso de las KW+, el color de los círculos muestra el grupo temático al que cada KW+ pertenece)
Tabla 3 Muestra de las cuatro KW+ con mayor peso dentro de cada clúster (el color aleatorio corresponde a los diferentes grupos temáticos identificados)

Cluster 1: investigaciones epidemiológicas y enfermedades infecciosas por virus (17%). Esta línea de investigación se centró en las enfermedades infecciosas, particularmente el impacto de la infección por el virus de inmunodeficiencia humana (VIH). En esta línea también destacó la corriente dedicada a la infección por el virus Influenza A H1N1. Este cluster incluyó 30 ítems, entre las KW+ con mayor peso o índice de similaridad se encontraron: Estados-Unidos, Epidemiología, Virus, Infección, Virus, VIH, AH1N1.
Cluster 2: calidad de vida relacionada con la salud (CVRS) (16%). Este frente de investigación se centró en los trabajos sobre CVRS y los factores sociales que influyen en la atención sanitaria. Este clúster agrupó a 28 ítems, tales como: Atención, Porcentaje, Calidad de Vida, Desigualdades, Acceso, Carga, Género, Personal Sanitario, Información, Migración, Servicios.
Cluster 3: atención primaria (11%). En este frente de investigación se vinculó con las tendencias y servicios en la atención primaria. Este cluster agrupó a 20 ítems con los términos nucleares como: Tendencias, Atención Primaria, Ejercicio, Control Glucémico, Comportamiento, Validación, Consumo de Alcohol.
Cluster 4: vigilancia en salud pública (10,8%). En este grupo temático se incluyeron diferentes aspectos relacionados con la vigilancia en salud pública para reducir la mortalidad. El cluster incluyó 19 ítems, entre las KW+ con mayor peso se encontraron: Salud, Mortalidad, Asociación, Adultos, Consumo, Comunidad, Países Europeos.
Cluster 5: prevención de enfermedades cardiovasculares (ECV) (9%). Este frente de investigación se centró en los programas de prevención y control de enfermedades cardiovasculares. Este cluster incluyó 16 ítems, las KW+ con mayor peso fueron: Población, Prevención, Obesidad, Enfermedad Coronaria, Actividad Física, Diagnóstico, Riesgo Cardiovascular, Hábito de Fumar, Práctica Clínica, Enfermedad Cardiovascular.
Cluster 6: investigaciones de políticas sanitarias en España (8,5%). Este frente de investigación aglutinó los trabajos sobre medicina pública y políticas sanitarias principalmente en España. Este cluster agrupó 15 ítems, las KW+ con mayor índice similaridad fueron: España, Salud Pública. Adolescentes, Niños, Intervención, Ensayo Clínico Controlado Aleatorio.
Cluster 7: gestión en salud pública (8,5%). Esta corriente centró el impacto y la gestión de políticas que apoyan los esfuerzos en salud pública. Este cluster agrupó 15 ítems, tales como: Gestión, Impacto, Práctica General, Morbilidad, Resultados, Estudio de Cohortes.
Cluster 8: programas de control de riesgos en salud pública (8%). Este grupo temático se centró en los programas, guías y recomendaciones para el control de riesgos en salud pública. Este cluster agrupó a 14 ítems, las KW+ con mayor peso fueron: Factores de Riesgo, Mujer, Directrices, Hombre, Programa.
Cluster 9: revisiones sistemáticas y meta-análisis (6,8%). Esta línea de investigación se relacionó con las aportaciones de las revisiones sistemáticas en relación con las enfermedades cardiovasculares. Incluyó 12 ítems, las KW+ con mayor peso fueron: Enfermedad, Riego, Meta-análisis, Infarto del Miocardio, Distribución Aleatoria.
Cluster 10: prevalencia de los factores de riesgo de las enfermedades cardiovasculares (4%). En esta línea se situaron los estudios de la prevalencia de los factores de riesgos las enfermedades cardiovasculares. Agrupó 7 ítems, con KW+ tales como: Prevalencia, Presión Sanguínea, Hipertensión, Factores de Riesgo Cardiovascular.
Con respecto al mapa bibliométrico de densidad, el tamaño de las etiquetas de las KW+ y el color de las diferentes zonas indicaron su nivel de relevancia (Figura 2), siguiendo el movimiento de las agujas del reloj, se destacaron los siguientes núcleos:

Figura 2 Mapa bibliométrico de densidad, en el que se representaron las 176 KW+ analizadas (los colores próximos al rojo muestran las zonas de mayor densidad de co-ocurrencias de KW+, los colores próximos al amarillo y verde muestran las zonas de menor densidad de co-ocurrencias de KW+)
Zona central del mapa (color rojo): se situaron, por su significativa centralidad y co-ocurrencia, las KW+ pertenecientes a las líneas de investigación consolidados como son el control de los factores de riesgo de enfermedades en una población (Población, Prevalencia, Mortalidad, Factor de Riesgo, España, Gestión) y la Epidemiología (Enfermedad, Terapia, Estudio de Cohortes, Resistencia, Epidemiología, Diagnóstico).
Zona periférica del mapa en el borde izquierdo inferior (color próximo al verde), se situaron las KW+ pertenecientes a líneas de investigación referidas a las enfermedades cardiovasculares: Enfermedad Cardiovascular, Infarto del Miocardio, Hombre.
Zona periférica del mapa en el borde izquierdo superior del mapa (color amarillo), se localizaron las KW+ referidas a dos tendencias de investigación relevante durante este período, como fueron los problemas de la infección por VIH y virus H1N1: Infección, Virus de la Inmunodeficiencia Humana, SIDA, Estados-Unidos, AH1N1.
Zona periférica del mapa en el borde derecho superior (color rojo y amarillo), se situaron KW+ con alta densidad perteneciente a una línea de investigación vinculada con la calidad de vida relacionada con la salud (CVRS), que abarcó aspectos multidimensionales relacionados con el estilo de vida y su influencia en la salud: Calidad de Vida, Atención, Porcentaje, Desigualdades, Acceso, Género.
Zona periférica del mapa en el borde derecho inferior (color amarillo), se situaron KW+ vinculadas a un frente de investigación emergente relacionado con los problemas del consumo episódico excesivo de alcohol (CEEA), también conocido como consumo intensivo de alcohol (CIA), principalmente en adolescentes: Salud Mental, Consumo de Alcohol, Trastornos.
DISCUSIÓN
El resultado de las visualizaciones obtenidas nos permite comprender la estructura temática de las principales líneas de investigación en salud pública a través de la publicación RESP durante el período 2006-2015. Sobre la base de la visualización del mapa bibliométrico etiquetado se pueden extraer una serie de conclusiones. Primera, el mapa revela que, en el período analizado, destaca una macro línea de investigación consolidada, que engloba los estudios sobre epidemiología, prevalencia y prevención de enfermedades así como el acceso de la población a los servicios de salud, los servicios de atención primaria, los programas de control de riegos, la organización de servicios médicos y la investigación en políticas de salud. Segunda, en este periodo se detecta un interés por las investigaciones epidemiológicas en relación a la infección por VIH y al esfuerzo internacional realizado para conseguir una remisión del virus así como un interés por la infección por virus Influenza A H1N1. Tercera, se muestra una importante línea temática vinculada con la prevalencia de las enfermedades cardiovasculares (ECV) así como el control de los factores de riesgo de las enfermedades coronarias. Cuarta, se observan varios grupos temáticos que aglutinan diferentes aspectos multidimensionales vinculados, por un lado, a la calidad de vida relacionada con la salud (CVRS) y el desarrollo de mecanismos sociales de acceso a la salud. Quinto, se identifica una línea emergente relacionada con el consumo episódico excesivo de alcohol (CEEA), principalmente en adolescentes.
En el análisis de los resultados del mapa bibliométrico de densidad pudimos observar con mayor claridad que las KW+ más importantes se situaron en el centro del mapa. El color de las nubes de conglomerados representó la fuerza de la relación de las KW+ en cada zona del mapa. El mapa de densidad nos permitió obtener un enfoque de las zonas en las cuales se concentran una mayor frecuencia de co-ocurrencia entre las KW+ con mayor peso. La metáfora de densidad fue muy útil para obtener una visión global de las KW+ más relevantes en cuanto a las corrientes de investigación representadas. Así la relevancia de un frente de investigación se determinó por el número de ítems dentro de ese cluster y por la densidad o co-ocurrencia de esos ítems. La conclusión general que hemos extraído es que las KW+ posicionadas en el centro del mapa son las que tienen mayor grado de interacción con el resto de las KW+, conformando, por tanto, los términos predominantes durante el período 2006-2015, core-terms, y se concentran en las siguientes: Población, Prevalencia, España, Mortalidad, Enfermedad, Factores de Riesgo, Estudios de Seguimiento, Prevención. Destaca también en el margen derecho inferior las KW+: Factores de Riego Cardiovascular, Hipertensión. En el margen derecho superior las KW+: Virus, Estados-Unidos. En el margen izquierdo superior destaca una zona periférica de alta densidad con KW+ tales como: Calidad de Vida, Atención, Acceso, Desigualdades. Y en el margen derecho inferior destaca el núcleo emergente con KW+ tales como: Salud Mental, Consumo de Excesivo de Alcohol.
Por último, podemos concluir que, debido al carácter intersectorial, multidisciplinar y multidimensional del dominio científico de la salud pública, los mapas bibliométricos mejoran la comprensión global de la estructura semántica y concetual de este campo de investigación.
En trabajos futuros, la construcción y comparación de mapas bibliométricos bidimensionales correspondientes a varios períodos temporales pondría mostrar hacía dónde evolucionan las tendencias y frentes de investigación en salud pública.

