










Mi SciELO
 Servicios personalizados
Servicios personalizadosServicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares en
SciELO
Similares en
SciELO -
 Similares en Google
Similares en Google
Compartir

 Permalink
PermalinkEscritos de Psicología (Internet)
versión On-line ISSN 1989-3809versión impresa ISSN 1138-2635
Escritos de Psicología vol.3 no.3 Málaga ago. 2010
Modelización de diseños split-plot y estructuras de covarianza no estacionarias: un estudio de simulación
Modelling split-plot data and nonstationary covariance structures: a simulation study
Roser Bono1, Jaume Arnau1, Guillermo Vallejo2
1Facultad de Psicología, Universidad de Barcelona
2Facultad de Psicología, Universidad de Oviedo
Este estudio ha sido financiado por los Proyectos de Investigación PSI2009-11136 y PSI2008-03624 del Plan Nacional I+D+I del Ministerio de Ciencia e Innovación.
Dirección para correspondencia
RESUMEN
Un tema que ha suscitado mayor interés entre los investigadores del análisis de datos longitudinales ha sido el desarrollo, a través de estudios de simulación, de modelos de análisis que incorporen aquellas estructuras de covarianza que mejor se ajusten a los datos. Al analizar las estructuras de covarianza en el ámbito de datos longitudinales, nos encontramos que no siempre las varianzas son constantes. Así, es frecuente que las varianzas incrementen con el tiempo cuando las correlaciones entre observaciones igualmente espaciadas no son homogéneas. En este trabajo llevamos a cabo un estudio de simulación, a fin de analizar dos estructuras de coeficientes aleatorios con correlaciones no estacionarias. La primera con varianzas constantes (RC) y la segunda, dada su utilidad en contextos longitudinales, con varianzas que presentan una estructura lineal (RCL). Una vez generadas ambas matrices de covarianza, RC y RCL, se ajustan once estructuras de covarianza mediante el PROC MIXED para el criterio Akaike, lo que permite seleccionar la de mejor ajuste. El objetivo de este estudio es conocer cuáles son los porcentajes de ajuste de las distintas matrices de covarianza y en que medida la de mejor ajuste es la matriz de covarianza de la población.
Palabras clave: Estructuras de covarianza, diseños split-plot, modelos de coeficientes aleatorios, criterio Akaike, simulación Monte Carlo.
ABSTRACT
A topic that has aroused great interest among researchers who analyse longitudinal data has been the development, by means of simulation studies, of analytic models that incorporate the covariance structures which best fit the data. When analysing covariance structures within the context of longitudinal data one finds that the variances are not always constant. Indeed, the variances commonly increase over time when the correlations between equally spaced observations are not homogeneous. This paper reports a simulation study which analysed two random coefficient models with nonstationary correlations. The first had constant variances (RC), while the second, given its utility in longitudinal contexts, showed variances with a linear structure (RCL). Once the two covariance matrices (RC and RCL) had been generated, eleven covariance structures were fitted by means of PROC MIXED for the Akaike criterion, thus enabling the best fit to be selected. The aim of the study was to determine the fit percentages of the different covariance matrices and the extent to which the one with the best fit corresponds to the population covariance matrix.
Keywords: Covariance structures, split-plot designs, random coefficient models, Akaike criterion, Monte Carlo simulation.
A lo largo de los últimos años ha habido un notable incremento de estudios longitudinales, tanto en ciencias sociales como psicológicas. Así, en una reciente revisión realizada sobre 10 revistas de psicología en los años 1999 y 2003, se concluye que si en 1999 el 33% de estudios publicados fueron longitudinales, en 2003 fue el 47% (Singer y Willet, 2005). En este mismo sentido, Bono, Arnau y Vallejo (2008), en una revisión bibliográfica de estudios longitudinales registrados en las bases de datos PsycInfo y Medline durante el período 1985-2005, constataron una creciente tendencia de investigaciones longitudinales. Estos datos corroboran el espectacular avance de los estudios de carácter longitudinal. Uno de los motivos del incremento de estos estudios es que el enfoque longitudinal, comparado con el transversal, es más eficiente, más robusto en la selección del modelo y estadísticamente más potente (Edwards, 2000; Helms, 1992; Zeger y Liang, 1992).
En lo que concierne al análisis de datos longitudinales, pueden seguirse diversos procedimientos (véase una revisión de los mismos en Arnau y Bono, 2008). Así, el enfoque basado en el modelo lineal mixto (MLM) asume que las observaciones constan de dos partes, los efectos fijos y los efectos aleatorios. Los efectos fijos son los valores esperados de las observaciones y los efectos aleatorios las varianzas y covarianzas de las observaciones. Mediante esta metodología, el investigador modela la estructura de covarianza y consigue una mayor robustez en la prueba de los efectos de medidas repetidas, así como de su interacción con el factor grupos. Laird y Ware (1982) propusieron las bases del MLM en que se tiene en cuenta la posible correlación de los errores intra-sujeto. Posteriormente, Cnaan, Laird y Slasor (1997) y Verbeke y Molenberghs (2000) presentaron una especificación más completa y aplicaron el MLM a datos longitudinales de medidas repetidas. A diferencia de los procedimientos clásicos, como el análisis univariante de la varianza (ANOVA) y el análisis multivariante de la varianza (MANOVA), el MLM afronta de forma directa el problema relativo a la modelación de la estructura de covarianza. Con el MLM se especifica, a partir de los datos, la estructura de la matriz de covarianza sin tener que presuponerla. Así, se consigue una estimación más eficiente de los efectos fijos y, en consecuencia, la obtención de pruebas estadísticas más potentes (Wolfinger, 1996). A su vez, el MLM no requiere datos balanceados y completos como ocurre con el ANOVA y el MANOVA, siendo esto de suma importancia puesto que los datos longitudinales suelen ser incompletos. Por ello, tal como destacan Littell, Milliken, Stroup y Wolfinger (1996), la mayoría de los procedimientos actuales aplican los métodos basados en el MLM con una estructura paramétrica especial de las matrices de covarianza. Así, lo que hace del análisis de medidas repetidas algo distinto es la estructura de covarianza de los datos observados.
El uso de modelos explícitos para definir la estructura de covarianza de los datos es uno de los temas más controvertidos entre los estudiosos del análisis de datos longitudinales. Núñez-Antón y Zimmerman (2001) destacan que el análisis de estructuras de covarianza no estacionarias en el contexto de datos longitudinales no se ha realizado de forma detallada. Núñez-Antón y Zimmerman (2000) concluyen que muchos de los modelos propuestos recientemente son no estacionarios, de forma que es posible modelizar varianzas no constantes y/o correlaciones que no sean sólo función del tiempo que separa a dos observaciones dadas. Esta clase de estructuras son bastante comunes en la mayoría de datos de carácter longitudinal. La estructura de covarianza más típica en datos longitudinales es la no-estructurada, dado que no exige ninguna asunción respecto a los términos de error y permite cualquier patrón de correlación entre las observaciones. Con estos modelos aplicables a datos longitudinales, se asume la no estacionariedad de varianzas y correlaciones (ecuación 1).
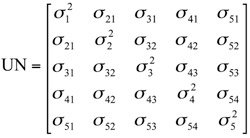
Otra estructura frecuente con datos longitudinales es la autorregresiva donde las correlaciones decrecen a medida que el tiempo de separación entre observaciones aumenta (ecuación 2). En este modelo, las varianzas son constantes y las correlaciones entre medidas equidistantes en el tiempo son las mismas.
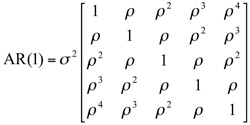
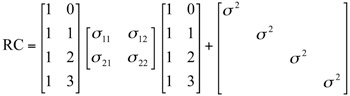
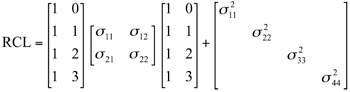
A diferencia de los modelos no-estructurados, estudiados en un trabajo previo (Arnau, Bono y Vallejo, 2009), hay otros modelos donde la no estacionariedad de los datos tiene una estructura con pocos parámetros (Núñez-Antón y Zimmerman, 2001). Por ejemplo, los modelos de coeficientes aleatorios pueden usarse para modelizar ciertos tipos de no estacionariedad (Diggle, Liany y Zeger, 1994). Estos modelos han sido propuestos en contextos de datos longitudinales y no han sido comparados con procedimientos Monte Carlo, particularmente con no estacionariedad en las varianzas. Así, en este trabajo estudiaremos dos estructuras de coeficientes aleatorios, una con varianzas constantes (RC) y otra con varianzas que presentan una estructura lineal (RCL):
En la práctica, cuando las varianzas son no-constantes y las correlaciones son no- estacionarias, puede que el ajuste del modelo sea incorrecto. De este modo, pretendemos hallar cuál es la estructura de varianza-covarianza de mejor ajuste en función de la cantidad de medidas repetidas, la homogeneidad/heterogeneidad de la matriz de covarianza entre-grupos, los tamaños de muestra y el índice de esfericidad.
El interés de este estudio de simulación radica en determinar la estructura de covarianza más adecuada, dado que cuando se modela de forma efectiva la estructura de covarianza se obtienen estimaciones más exactas (con menor sesgo) y también más precisas (con menor varianza) de los parámetros del modelo (Vallejo, Arnau, Bono, Fernández y Tuero, 2010). Con el fin de hallar los porcentajes de ajuste a la estructura RC de distintas matrices de covarianza y compararlos con los de la estructura RCL, más común en datos de carácter longitudinal, se usa el programa PROC MIXED del sistema SAS.
Método de simulación
La modalidad de diseño split-plot simulada en este trabajo incluye un factor entre-sujetos, donde los sujetos (i = 1,...,nj) son elegidos al azar para cada grupo (j = 1,...,J), y un factor intra-sujetos de medidas repetidas (k = 1,...,K). El objetivo de esta clase de diseño es estudiar el efecto principal de medidas repetidas y la interacción grupos x medidas repetidas. Se asume que los datos se distribuyen normalmente.
Variables del estudio
El análisis de los diseños split-plot se ha llevado a cabo con diseños balanceados y no balanceados, con un factor entre sujetos y un factor intra sujetos. Del factor entre sujetos se tomaron tres valores y del factor intra los valores cuatro, seis y ocho. En el trabajo de simulación se han seleccionado las combinaciones de cinco factores para cada nivel de K: a) estructura de covarianza de la población, b) estructura de covarianzas entre-grupos homogéneas y heterogéneas, c) tamaños de muestra total, d) tamaños de grupo iguales y desiguales y e) emparejamientos de las matrices de covarianza y tamaños de grupos.
A fin de generar los datos, se usaron dos estructuras de covarianza con heterogeneidad intra-sujeto: RC y RCL. La estructura RC presenta varianzas constantes y la RCL varianzas que mantienen entre sí una relación lineal, ya que con datos longitudinales es frecuente que las varianzas incrementen con el tiempo (Núñez-Antón y Zimmerman, 2000, 2001). A su vez, se investigó la violación del supuesto de esfericidad, tomándose los índices ε = 0,57 y 0,75. Cuando ε = 1, se satisface el supuesto de esfericidad con diseños J x K, mientras que con ε = 1/(K-1) el índice toma el valor opuesto o extremo. La mayoría de trabajos utilizan como buena aproximación a la esfericidad el valor de 0,75, mientras que para la no-esfericidad usan el valor 0,57 (Arnau et al., 2009; Algina y Keselman, 1998; Keselman, Algina, Kowalchuk y Wolfinger, 1999; Lix, Algina y Keselman, 2003). La Tabla 1 muestra los valores de las matrices de covarianza para los índices de esfericidad correspondientes a estructuras de cuatro medidas repetidas. Omitimos reproducir los valores de las matrices de covarianza generadoras correspondientes a estructuras de 6 y 8 medidas repetidas.

En la Tabla 2 se resumen las distintas combinaciones de las variables examinadas en este estudio. De cada combinación se han realizado 1000 réplicas a un nivel de significación de 0,05: K x estructuras de covarianza x ε x combinaciones N(n1 n2 n3)/Δnj/covarianzas entre-grupos/emparejamiento x replicas (3 x 2 x 2 x 12 x 1000 = 144.000).
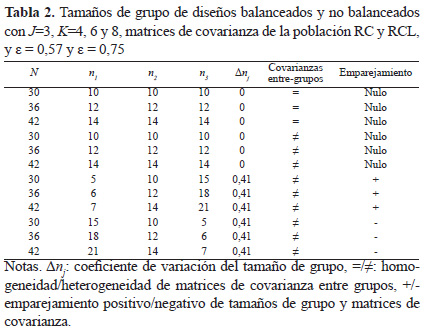
Estructuras de covarianza ajustadas a los datos
Teniendo en cuenta la heterogeneidad tanto intra como entre-sujetos, se ajustaron 11 estructuras de covarianza con el PROC MIXED para el criterio AIC, a fin de seleccionar la de menor valor. Se ajustaron las siguientes matrices de covarianza: a) simetría compuesta (CS), b) no estructurada (UN), c) autorregresiva de primer orden (AR), d) esférica de Huynh-Feldt (HF), e) simetría compuesta heterogénea intra-sujetos (CSH), f) autorregresiva de primer orden heterogénea intra-sujetos (ARH), g) de coeficientes aleatorios (RC), h) no estructurada heterogénea entre-sujetos (UNj), i) esférica de Huynh-Feldt heterogénea entre-sujetos (HFj), j) autorregresiva de primer orden heterogénea intra y entre-sujetos (ARHj) y k) de coeficientes aleatorios heterogénea entre-sujetos (RCj), donde el subíndice j indica que las matrices de covarianza no son iguales entre los grupos.
Resultados
En el estudio de simulación, se determinó la estructura de covarianza seleccionada mediante el criterio AIC de entre 11 estructuras de covarianza (CS, UN, AR, HF, CSH, ARH, RC, UNj, HFj, ARHj y RCj). Las Tablas 3 y 4 muestran los porcentajes de ajuste de las 11 matrices a las estructuras de covarianza generadas, en función de las distintas combinaciones de las variables estudiadas. Cabe destacar que con covarianzas entre-grupos homogéneas se utilizaron las matrices de la población RC y RCL y con covarianzas heterogéneas, RCj y RCLj.
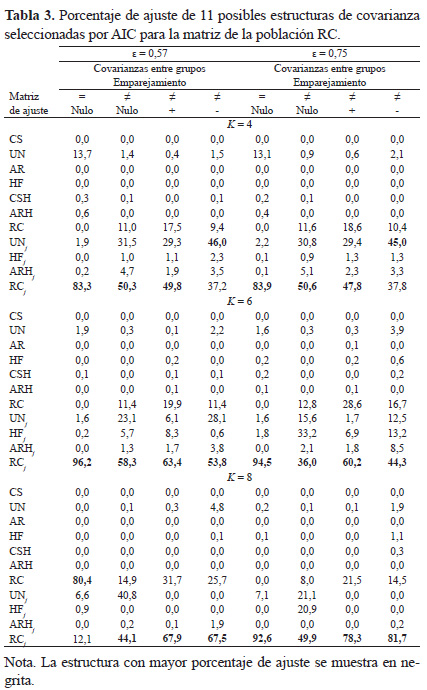
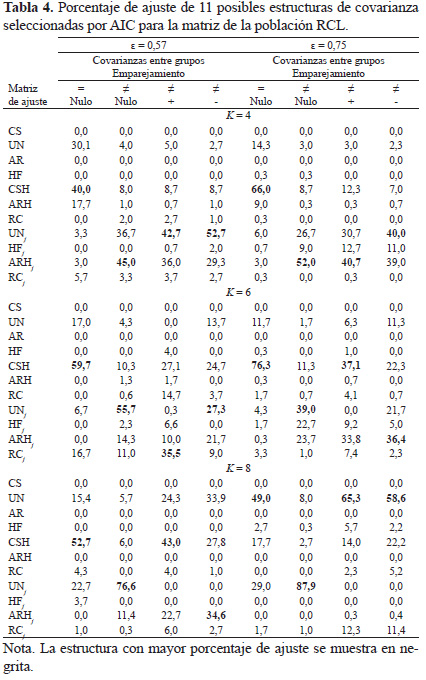
En el presente trabajo se optó por el criterio de ajuste AIC por comportarse mejor que el criterio de información bayesiana (BIC). Keselman, Algina, Kowalchuk y Wolfinger (1998) comprobaron que el criterio AIC elige el 47% de las veces la estructura de covarianza poblacional verdadera, mientras que el criterio BIC escoge correctamente un 35%. Ferron, Dailey y Yi (2002) también comprobaron que AIC selecciona la estructura de covarianza verdadera en un 79% y el criterio BIC el 66%. Gomez, Schaalje y Fellingham (2005) concluyen que AIC tiene mayores tasas de éxito con estructuras de covarianza complejas como por ejemplo la UN. Más recientemente, Vallejo, Ato y Valdés (2008) comprobaron que con tamaños de grupo diferentes, el criterio AIC es el mejor para estimar los errores estándar. Por todo ello, hemos realizado un estudio de simulación utilizando el criterio AIC. No obstante, el criterio AIC no siempre selecciona la estructura verdadera, dado que otras estructuras pueden proporcionar aproximaciones adecuadas. A nuestro entender, la única forma de conocer si el modelo realmente ajusta los datos es comparar la matriz de varianzas y covarianzas de la población con la empírica. Aunque no hemos incluido esta comparación, hemos constatado una coincidencia entre ambas bastante aceptable cuando el porcentaje de ajuste es superior al 60%.
Homogeneidad de covarianzas entre grupos
En términos generales, la Tabla 3 muestra que con covarianzas homogéneas, la estructura que mejor se ajusta a las matrices RC, es la RCj (83,3-96,2%), tanto si se viola el supuesto de esfericidad (ε = 0,57) como si es cercano a la unidad (ε=0,75). Sólo en el caso K = 8 y ε = 0,57, la matriz RC muestra un mejor ajuste (80,4%). Con matrices de covarianza RCL (Tabla 4), la estructura seleccionada más frecuentemente es la CSH (40-76,3%), a excepción del caso K = 8 y ε = 0,75, donde la matriz de mejor ajuste es la UN (49%).
Heterogeneidad de covarianzas entre grupos
La Tabla 3 muestra que con matrices de covarianza heterogéneas RC, la estructura que mejor se ajusta es la RCj (36-81,7%). Por el contrario, cuando el emparejamiento es negativo y K = 4, se ajusta mejor la matriz UNj tanto con ε = 0,57 (46%) como con ε = 0,75 (45%). Con matrices de covarianza RCL son varias las estructuras que muestran un mayor porcentaje de ajuste (Tabla 4). Así, cuando las matrices de covarianza son heterogéneas, el ajuste de la matriz UNj oscila entre 27,3-87,9% y el ajuste de la matriz ARHj se halla entre 34,6-52%. En el caso de K=8, ε = 0,75 y emparejamientos no nulos, la estructura UN es la que mejor se ajusta: con emparejamiento positivo el porcentaje es de 65,3% y con emparejamiento negativo de 58,6%. Por último, las estructuras menos frecuentes que muestran un mejor porcentaje de ajuste son CSH y RCj.
Discusión
Hasta mediados de los noventa, la primera desventaja de los modelos que ajustan las matrices de covarianza fue la ausencia de paquetes estadísticos que permitiesen dicho ajuste. Actualmente, el paquete estadístico SAS 9.1.3, con su PROC MIXED ha logrado que muchos de estos modelos se puedan ajustar y comparar a otros modelos alternativos. Los modelos CS, UN, AR, HF, CSH, ARH, RC, UNj, HFj, ARHj y RCj son definibles con el PROC MIXED, aunque en los modelos RC es posible que existan problemas de convergencia con el algoritmo. Sin embargo, todavía existen algunos modelos, como por ejemplo el RCL, que no pueden ajustarse.
La elección de la estructura de covarianza puede realizarse con el uso de gráficos, con la comparación de las estimaciones de covarianza y con la utilización de índices de ajuste que es la opción utilizada en este estudio. Es importante señalar que las estimaciones de los efectos fijos con distintas estructuras de covarianza pueden presentar los mismos valores, aunque los errores estándar de estas estimaciones varíen en gran medida. En consecuencia, las pruebas de significación dependen de la estructura de covarianza elegida, aunque no así las estimaciones de los efectos fijos. Ello tiene una mayor repercusión cuando los datos no están balanceados o bien los intervalos de tiempo entre las observaciones no son constantes.
El estudio de simulación nos ha permitido seleccionar las matrices de covarianza de mejor ajuste según el criterio AIC. Con ello se tienen en cuenta los posibles sesgos debidos a una elección errónea que influyen en la robustez del estadístico utilizado (Vallejo et al., 2008). Con homogeneidad y heterogeneidad de covarianzas y matrices RC, hallamos que la estructura RCj se ajusta con un porcentaje elevado. No ocurre lo mismo con matrices de covarianza RCL. En este caso, cuando las matrices de covarianza son homogéneas, la estructura de mejor ajuste es la CSH y cuando las matrices de covarianza son heterogéneas, han sido diversas las estructuras que pueden ajustarse, la más frecuente la UNj. Además, cabe destacar que estos porcentajes no son tan elevados como cuando la matriz de población es la RC. Estos resultados nos indican la dificultad ante la que nos encontramos cuando la matriz poblacional es RCL, puesto que el PROC MIXED no tiene incorporada dicha matriz para su ajuste.
Nuestro principal objetivo ha sido ilustrar, mediante un estudio de simulación, qué ocurre ante la existencia de no estacionariedad en las varianzas en modelos de coeficientes aleatorios. Es decir, hallar los posibles modelos que permiten explicar estos comportamientos no estacionarios. Así, comparamos el ajuste de estos modelos a matrices RCL con el ajuste de los mismos modelos a matrices RC. El interés especial de este trabajo está en que el modelo RCL es muy frecuente con datos de carácter longitudinal y no se tiene en cuenta en el PROC MIXED del SAS. Cuando este es el caso, debemos ser muy reticentes con el uso del PROC MIXED.
Otro aspecto interesante de abordar en futuros estudios sería replicar el mismo trabajo de simulación pero con datos que no se distribuyan normalmente, puesto que es sabido que las distribuciones encontradas en contextos de investigaciones reales se alejan de la normalidad Por ejemplo, del trabajo de Micceri (1989) se desprende que las distribuciones más frecuentes encontradas en la literatura científica son moderadamente asimétricas y con una curtosis extremadamente desviada de la normal.
Referencias
Algina, J. y Keselman, H. J. (1998). A power comparison of the Welch-James and Improved General Approximation tests in the split-plot designs. Journal of educational and Behavioral Statistics, 23, 152-169. [Full text via CrossRef] [ Links ]
Arnau, J. y Bono, R. (2008). Estudios longitudinales. Modelos de diseño y análisis. Escritos de Psicología, 2, 30-39. [Link] [ Links ]
Arnau, J., Bono, R. y Vallejo, G. (2009). Analyzing small samples of repeated measures data with the mixed-model adjusted F test. Communications in Statistics. Simulation and Computations, 38, 1083-1103. [Full text via CrossRef] [ Links ]
Bono, R., Arnau, J. y Vallejo, G. (2008). Técnicas de análisis aplicadas a datos longitudinales en Psicología y Ciencias de la Salud: Período 1985-2005. Papeles del Psicólogo, 29, 136-146. [ Links ]
Cnaan, A., Laird, N. M. y Slasor, P. (1997). Using the general linear mixed model to analyze unbalanced repeated measures and longitudinal data. Statistics in Medicine, 16, 2349-2380. Full text via CrossRef available at http://dx.doi.org/10.1002/(SICI)1097-0258(19971030)16:20<2349::AID-SIM667>3.0.CO;2-E [ Links ]
Diggle, P. J., Liang, K. Y. y Zeger, S. L. (1994). Analysis of longitudinal data. New York: Oxford University Press. [ Links ]
Edwards, L. J. (2000). Modern statistical techniques for the analysis of longitudinal data in biomedical research. Pediatric Pulmony, 30, 330-344. Full text via CrossRef available at http://dx.doi.org/10.1002/1099-0496(200010)30:4<330::AID-PPUL10>3.0.CO;2-D [ Links ]
Ferron, J., Dailey, R. y Yi, Q. (2002). Effects of misspecifying the first-level error structure in two-levels models of change. Multivariate Behavior Research, 37, 379-403. [Full text via CrossRef] [ Links ]
Gomez, E. V., Schaalje, G. B. y Fellingham, G. W. (2005). Performance of the Kenward-Roger method when the covariancia structure is selected using AIC and BIC. Communication in Statistics. Theory and Methods, 34, 377-392. [ Links ]
Helms, R. W. (1992). Intentionally incomplete longitudinal designs: I. Methodology and comparison of some full span designs. Statistics in Medicine, 11, 1889-1993. [Full text via CrossRef] [ Links ]
Keselman, H. J., Algina, J., Kowalchuk R. K. y Wolfinger, R. D. (1998). A comparison of two approaches for selecting covariance structures in the analysis of repeated measurements. Communications in Statistics. Simulation and Computation, 27, 591-604. [Full text via CrossRef] [ Links ]
Keselman, H. J., Algina, J., Kowalchuk R. K. y Wolfinger, R. D. (1999). A comparison of recent approaches to the analysis of repeated measurements. British Journal of Mathematical and Statistical Psychology, 52, 63-78. [Full text via CrossRef] [ Links ]
Keselman, H. J., Carriere, K. C. y Lix, L. M. (1993). Testing repeated measures hypotheses when covariance matrices are heterogeneous. Journal of Educational Statistics, 18, 305-319. [Full text via CrossRef] [ Links ]
Laird, N. M. y Ware, J. H. (1982). Random effects models for longitudinal data. Biometrics, 38, 963-974. [Full text via CrossRef] [ Links ]
Littell, R. C., Milliken, G. A., Stroup, W. W. y Wolfinger, R. D. (1996). SAS system for mixed models. Cary, NC: SAS Institute. [ Links ]
Livacic-Rojas, P., Vallejo, G. y Fernández, P. (2006). Procedimientos estadísticos alternativos para evaluar la robustez mediante diseños de medidas repetidas. Revista Latinoamericana de Psicología, 38, 579-599. [ Links ]
Lix, L. M., Algina, J., Keselman, H. J. (2003). Analyzing multivariate repeated measures designs: A comparison of two approximate degrees of freedom procedures. Multivariate Behavioral Research, 38, 403-431. [Full text via CrossRef] [ Links ]
Micceri, T. (1989). The unicorn, the normal curve, and other improbable creatures. Psychological Bulletin, 105, 156-166 [Full text via CrossRef] [ Links ]
Núñez-Antón. V. y Zimmerman, D. L. (2000). Modeling nonstationary longitudinal data. Biometrics, 56, 699-705. [Full text via CrossRef] [ Links ]
Núñez-Antón. V. y Zimmerman, D. L. (2001). Modelización de datos longitudinales con estructuras de covarianza no estacionarias: modelos de coeficientes aleatorios frente a modelos alternativos. Qüestió, 25, 225-262. [ Links ]
SAS Institute. (1997). SAS Macro language: Reference. Cary, NC: Author. [ Links ]
SAS Institute. (1999a). SAS/IML software, usage and reference, Version 8. Cary, NC: Author. [ Links ]
SAS Institute. (1999b). SAS Language reference: Dictionary, Version 8. Cary, NC: Author. [ Links ]
Singer, J. D. y Willett, J. B. (2005). Longitudinal research: Current status and future prospects. Consulta 12 de septiembre de 2007 de la World Wide Web: http://gseweb.harvard.edu/~faculty/singer/Presentations/Longitudinal research.ppt. [ Links ]
Vallejo, G., Arnau, J., Bono, R., Fernández, P. y Tuero, E. (2010). Selección de modelos anidados para datos longitudinales usando criterios de información y la estrategia de ajuste condicional. Psicothema, 22, 323-333. [ Links ]
Vallejo, G. y Ato, M. (2006). Modified Brown-Forsythe procedure for testing interactions effects in split-plot designs. Multivariate Behavioral Research, 41, 549-578. [Full text via CrossRef] [ Links ]
Vallejo, G., Ato, M. y Valdés, T. (2008). Consequences of misspecifying the error covariance structure in linear mixed models for longitudinal data. Methodology. European Journal of Research for the Behavioral and Social Sciences, 4, 10-11. [ Links ]
Vallejo, G., Fidalgo, A. y Fernández, P. (2001). Effects of covariance heterogeneity on three procedures for analyzing multivariate repeated measures designs. Multivariate Behavioral Research, 36, 1-27. [Full text via CrossRef] [ Links ]
Verbeke, G. y Molenberghs, G. (2000). Linear Mixed Models for Longitudinal Data. New York: Springer-Verlag. [ Links ]
Wolfinger, R. D. (1996). Heterogeneous variance-covariance structures for repeated measurements. Journal of Agricultural, Biological, and Enviromental Statistics, 1, 205-230. [Full text via CrossRef] [ Links ]
Zeger S. L. y Liang, K. Y. (1992). An overview of methods for the analysis of longitudinal dada. Statistics in Medicine, 11, 1825-1839. [Full text via CrossRef] [ Links ]
![]() Dirección para correspondencia:
Dirección para correspondencia:
Roser Bono
Departament de Metodologia de les Ciències del Comportament
Facultat de Psicologia
Universitat de Barcelona
Passeig de la Vall d'Hebron 171
08035-Barcelona
Tel.: 93 312 50 80
Fax: 93 402 13 59
E-mail: rbono@ub.edu
Fecha de recepción: 29 de marzo
Fecha de aceptación: 29 de abril

