










Mi SciELO
 Servicios personalizados
Servicios personalizadosServicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares en
SciELO
Similares en
SciELO -
 Similares en Google
Similares en Google
Compartir

 Permalink
PermalinkEscritos de Psicología (Internet)
versión On-line ISSN 1989-3809versión impresa ISSN 1138-2635
Escritos de Psicología vol.10 no.2 Málaga may./ago. 2017
https://dx.doi.org/10.5231/psy.writ.2017.2802
Efecto de la riqueza semántica en distintos niveles del procesamiento léxico-semántico
Semantic richness effect at different levels of lexical-semantic processing
Mauro Fragapane y Leticia Vivas
Facultad de Psicología. Universidad Nacional de Mar del Plata, Buenos Aires, Argentina
Este trabajo se realizó en el marco de una beca Estímulo a la Vocación Científica financiada por el Concejo Interinstitucional Nacional (CIN) de la República Argentina otorgada al primer autor.
Dirección para correspondencia
RESUMEN
La riqueza semántica es un constructo multidimensional que refleja la extensión de la variabilidad de la información asociada con el significado de una palabra. Una de las dimensiones de este constructo que ha demostrado tener mayor influencia en el procesamiento léxico y semántico es el número de atributos (NdA). Numerosos trabajos están aportando evidencia de que los conceptos que contienen mayor NdA permiten realizar un procesamiento lexical más rápido que los que poseen menor NdA. El presente trabajo es el primero en utilizar una medida de NdA basada en Normas obtenidas de una muestra de hispanoparlantes y se propone estudiar el efecto de esta variable en el reconocimiento visual de palabras. Se trabajó con una muestra de 90 adultos jóvenes universitarios hablantes de español. Se administraron tareas que requieren el acceso a distintos niveles de procesamiento léxico-semántico: decisión léxica, categorización semántica por concreción (concreteness) (concreto / abstracto) y categorización semántica por dominio (vivo / no-vivo). Los resultados indican un efecto de la riqueza semántica en las tareas de decisión léxica y categorización semántica por dominio con mayor peso en esta última. Se realiza una lectura de los resultados en el marco del modelo de activación interactivo de dominio general.
Palabras clave: Riqueza Semántica; Número de Atributos; Decisión léxica; Categorización Semántica.
ABSTRACT
Semantic richness is a multidimensional construct that refers to the extent of variability of information associated with the meaning of a word. The Number of Features (NoF) is a dimension of semantic richness that has been shown to have a major influence on lexical and semantic processing. Several studies have shown that concepts with a higher NoF allow faster lexical processing than those with a lower NoF. The current study is the first to use a NoF measure based on norms obtained from a sample of Spanish-speaking participants. The aim was to study the effect of this variable in visual word recognition. The sample included 90 young native Spanish-speaking adults. Three tasks were administered that require access to different lexico-semantic levels: lexical decision, concreteness semantic categorization (concrete/abstract), and domain semantic categorization (living/non-living). A semantic richness effect was found in lexical decision and domain semantic categorization tasks, with greater effect in the latter task. Results are interpreted within the framework of the General Domain Interactive Activation model.
Key words: Semantic Richness; Number of Features; Lexical Decision; Semantic Categorization.
Introducción
Son numerosas las variables que influyen en el procesamiento del significado de las palabras que son presentadas por vía visual. Estas variables generan un impacto en distintos niveles: fonológico, léxico y semántico. El presente estudio se focaliza en una variable de sumo interés en este último nivel: la riqueza semántica. La misma es un constructo multidimensional que refleja la extensión de la variabilidad de la información asociada con el significado de una palabra (Yap, Tan, Pexman y Hargreaves, 2011).
Algunos autores propusieron una serie de dimensiones dentro de este constructo. Por ejemplo, Yap, Pexman, Wellsby, Hargreaves y Huff (2012) menciona seis dimensiones: el número de atributos (NdA), la densidad de sus vecinos semánticos, el número de primeros asociados en tareas de asociación de palabras, la imaginabilidad (la medida en la cual evoca imágenes de objetos o eventos), el número de sentidos asociados a la palabra y la interacción cuerpo-objeto (la medida en que el cuerpo humano puede interactuar con el objeto). La dimensión seleccionada para medir la Riqueza semántica en esta investigación ha sido el Número de Atributos (NdA). Esta dimensión ha demostrado tener mayor influencia en el procesamiento léxico y semántico (Pexman, Hargreaves, Siakaluk, Bodner, y Pope 2008; Yap, et al., 2011; Yap et al., 2012). Se entiende por NdA al número que refleja la cantidad de atributos definidores que posee un concepto. Numerosos trabajos han arribado a la conclusión de que los conceptos que contienen mayor NdA permiten realizar un procesamiento lexical más rápido que los que poseen menor NdA (Grondin,Lupker y McRae, 2009; Pexman, Lupker y Hino, 2002; Pexman, Hargreaves, Siakaluk, Bodner, y Pope 2008; Yap, Pexman, Wellsby, Hargreaves, y Huff, 2012; Sajin y Connine, 2014).
Se ha demostrado que se responde más rápido a los conceptos con más NdA en tareas de decisión léxica (Grondin, Lupker, y McRae, 2009; Pexman et al., 2008; Sajin y Connine, 2014; Yap et al., 2012), tareas de reconocimiento visual de palabras (Pexman et al., 2008) y de categorización semántica por concreción (concreteness) (Grondin et al., 2009; Yap et al., 2011; Yap et al. 2012). Sin embargo, el efecto de la cantidad de atributos no es unívoco y depende del tipo de requerimiento de la tarea tal como demostraron algunos estudios (Hino, Pexman, y Lupker, 2006; Sajin y Connine, 2014; Yap et al., 2012).
La mayor parte de los trabajos se han centrado en dos tipos de tareas: Tarea de Decisión Léxica (TDL) y Tarea de Categorización Semántica por Concreción (concreteness) (TCSC). Como se puede inferir la primera tarea es principalmente léxica y la segunda semántica. Hay modelos teóricos que han propuesto explicaciones de este efecto de variables semánticas en tareas de tipo léxico. Por ejemplo, el modelo de activación interactiva de dominio general propuesto por Chen y Mirman (2012) que supone una arquitectura que incluye 3 niveles: fonemas/ letras, formas de la palabra y semántico. Las conexiones entre los niveles son bidireccionales, indicando que existe una influencia del procesamiento semántico en el procesamiento de las formas y viceversa. El modelo de activación interactiva consiste en unidades de procesamiento simples organizadas en tres capas: las unidades en la primera capa corresponden a los elementos de la forma de la palabra (es decir, los fonemas o letras), las unidades de la segunda capa corresponden a los elementos léxicos (es decir, palabras en el modelo léxico), y unidades en la tercera capa correspondían a los elementos del significado (es decir, los rasgos semánticos de los conceptos denotados por las palabras). La activación interactiva y la competencia de hecho dan cuenta de la pauta compleja de relaciones entre representaciones semánticas. Este modelo asume que la activación puede circular de manera bidireccional entre los niveles y que el procesamiento es en cascada (es decir que ni bien comienza el procesamiento en un nivel, éste envía activación al nivel siguiente). Dentro de este marco es posible explicar el efecto de algunas medidas de riqueza semántica sobre el procesamiento léxico suponiendo un proceso de retroalimentación mediante el cual las palabras con mayor riqueza semántica generarían mayor actividad en el nivel semántico resultando en una mayor retroalimentación hacia el nivel léxico (Balota, 1990). Por otra parte, cabe mencionar que trabajos recientes sugieren que la activación en cascada sólo se daría entre el nivel léxico y el semántico, mientras que entre los niveles de la letra (o fonema) y léxico sería por umbral (hasta no llegar a cierto nivel de activación no se pasa al nivel siguiente) (Yap y Pexman, 2015).
En el presente trabajo se agrega a las tareas tradicionalmente utilizadas para evaluar los efectos de la riqueza semántica, una tarea en la que suponemos tiene mayor peso el nivel semántico: una Tarea de Categorización Semántica por Dominio (TCSD). Se incluyó esta tarea dado que se asume que la misma implica el acceso a los atributos que conforman la representación del concepto. Para saber si un concepto es o no un ser vivo hay que recurrir a sus atributos. Por ejemplo, manzana es un objeto de la naturaleza pero puede considerarse no vivo. Con lo cual, para categorizarlo debemos valorar sus propiedades para dar cuenta de su cualidad o no de ser viviente. En este caso sería necesario acceder a sus propiedades para tomar la decisión. Para ello, probablemente se valore si cumple con los requisitos de tener un ciclo vital, respirar, requerir alimento, etc. De este modo, hipotetizamos que esta tarea tendrá un mayor efecto el número de atributos que en las anteriores. Esto iría de acuerdo al modelo de activación interactiva de Chen y Mirman (2012) pero indicaría también que habría un gradiente en el efecto de la riqueza semántica que disminuiría en las tareas léxicas y aumentaría en las semánticas. Por otra parte, hasta ahora no había una medida de esta variable (NdA) recolectada a partir de una muestra de habla hispana. El presente trabajo cuenta con la novedad de que es el primero en el que se utiliza una medida empírica de NdA basada en una muestra de hispanoparlantes argentinos.
Método
Se llevó a cabo un diseño cuasi-experimental de corte transversal.
Muestra
Para este estudio se utilizó una muestra de 90 adultos residentes en la ciudad de Mar del Plata (Argentina) (52% hombres). Estos participantes cumplían con el requisito de haber accedido a un nivel de estudios universitario, siendo los mismos estudiantes y/o graduados de diferentes carreras. Sus edades estaban comprendidas entre los 20 y los 40 años, presentando un promedio de 25 años. Presentaban visión normal o corregida a normal. Todos eran hablantes nativos de idioma español. Participaron 30 sujetos por tarea. Los grupos estuvieron conformados de manera homogénea en cuanto a edad y nivel educativo ya que fueron criterios de inclusión que su edad estuviera comprendida entre 20 y 40 años (véase Tabla 1) y que fuera estudiante universitario o graduado reciente. No hubo diferencias estadísticamente significativas entre los grupos en cuanto a la edad (F = 0,478; p = 0,622). Los participantes accedieron a formar parte de la muestra de manera voluntaria e informada por medio de consentimiento informado. El estudio siguió los principios establecidos en la Declaración de Helsinky (2013) para estudios en humanos.

Tareas
Se plantearon tres tareas con distinto nivel de profundidad de procesamiento, que se extiende desde el nivel léxico hasta el semántico: una Tarea de Decisión Léxica (TDL) (palabra-no palabra), una Tarea de Categorización Semántica por Concreción (concreteness) (TCSC) (concreto-abstracto) y una Tarea de Categorización Semántica por Dominio (TCSD) (vivo-no vivo). La resolución de estas tareas no contaba con un límite de tiempo establecido aunque se les sugirió a los participantes que lo resolviera tan rápidamente como pudieran.
Materiales
Se seleccionaron las mismas 80 palabras concretas para las tres tareas. Las mismas pertenecían a los nombres correspondientes a las imágenes del set propuesto por Cycowicz, Friedman, Rothstein y Snodgrass (1997). Este grupo de 80 palabras estaba compuesto conceptos pertenecientes a ambos dominios (vivos y no-vivos) 40 de los cuales tenían alto NdA (se incluyeron en esta variable los atributos taxonómicos) y 40 con bajo NdA de acuerdo con las Normas de Producción de Atributos Semánticos en español (Vivas, Vivas, Comesaña, Coni, Vorano, 2017). Se seleccionaron palabras de dos o tres sílabas y de niveles altos y bajos de Familiaridad y EdA. Los valores de Familiaridad y EdA fueron obtenidos de las normas argentinas de Manoiloff et al. (2010). También se incluyeron en los análisis otras variables de reconocida influencia en el procesamiento léxico-semántico: Frecuencia Léxica, Imaginabilidad, Concreción (concreteness) (Martínez-Cuitiño, Barreyro, Wilson, y Jaichenco, 2015), Cantidad de Fonemas y Densidad (Vivas, et al., 2017). Los valores promedios se pueden observar en la Tabla 2.
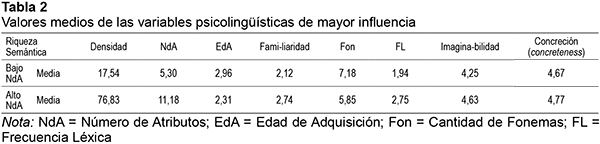
Además, para la tarea de Decisión Léxica se utilizaron 80 pseudopalabras y para la de Categorización Semántica por concreción (concreteness) 80 palabras abstractas. Estas últimas 160 palabras fueron utilizadas como estímulos auxiliares con la finalidad de completar la estructura de la tarea, de modo tal que permita su correcto desarrollo. No se realizó un análisis de los tiempos de respuesta sobre estos estímulos. Las pseudopalabras estuvieron compuestas por dos o tres sílabas igual que las palabras experimentales y se conformaron cambiando alguna letra de alguna palabra real tal como proponen Alija y Cuetos (2006). En cuarto lugar, la mayoría de las palabras abstractas fueron extraídas de la base de datos proporcionada por Algabel, S. (1996). Cabe mencionar también que se utilizaron 10 estímulos de práctica para cada una de las tareas. Estos elementos obviamente no fueron utilizados en las tareas experimentales propiamente dichas. En los Apéndices A a E se detallan los estímulos utilizados.
Procedimiento
Se evaluó a los participantes en sesiones individuales de 30 minutos de duración aproximada. La administración de las tareas se llevó a cabo en habitaciones silenciosas e iluminadas sin la presencia de estímulos intrusivos. Se utilizó para la administración de las tareas una Pc modelo Compac Presario CQ400-300LA. La presentación de los estímulos se realizó mediante el programa E-Prime 2.0. Luego de establecer el consentimiento informado, se los invitó a sentarse en un asiento cómodo frente a la computadora. Se prosiguió a comunicar la consigna proyectada en la pantalla de la computadora. Los participantes tuvieron que responder mediante teclado presionando el botón correspondiente a cada opción. Por eso se les indicó como debían posicionar los dedos en el teclado para lograr responder lo más rápido posible ante la presentación de los estímulos. Para cada tarea se presentaran 10 ensayos de práctica; se continuó con la tarea si se alcanzaba un 80% de aciertos en esta instancia siguiendo la metodología utilizada en Sajín y Connine (2014). Se registraron los aciertos de cada uno de los sujetos en las tareas así como el tiempo de respuesta a cada estímulo.
Para la TDL se les mostró a los participantes palabras y pseudopalabras y se los solicitó que indicaran lo más rápido posible si lo que observaban era una palabra verdadera o inventada. Para la tarea TCSC se les solicitó que indicaran si se trataba de una palabra concreta o abstracta. Por último, para la TCSD se les pidió que clasificaran las palabras en dos categorías posibles: vivo o no-vivo.
Análisis de los datos
El análisis de datos fue realizado mediante el Paquete Estadístico para las Ciencias Sociales (SPSS), en su versión 19.0. Es importante señalar que se realizó una depuración de los datos siguiendo el procedimiento utilizado por Pexman, Holyk y Monfiels (2003). Se eliminaron las respuestas incorrectas como también las respuestas cuyos tiempos hubieran sido mayores 1500 milisegundos y menores a 250 milisegundos. Con los datos conservados, en primer lugar, se calcularon estadísticos descriptivos y de diferencia de medias mediante prueba t considerando al NdA de manera dicotómica (alto vs bajo número de atributos). Luego se buscó estudiar el efecto del NdA en el tiempo de respuesta mediante un análisis de regresión lineal, en este caso tomando los valores particulares de cada concepto generando una variable continua. Finalmente se realizó una análisis de regresión multivariado para medir la influencia de una serie de variables de reconocida influencia en este tipo de tareas. Para ello se realizó un análisis de regresión para cada tarea donde se tomó como variable dependiente el tiempo de respuesta y como co-variables el NdA y las variables psicoligüísticas. Se utilizó el método paso a paso mediante el cual se van incluyendo por etapas aquellas variables de mayor poder explicativo en la varianza de los datos y se conservan las que tienen mayor correlación con la variable dependiente (Aron y Aron, 2001).
Resultados
El tiempo promedio de respuesta para la TDL fue de 813 milisegundos (DS = 119), para TCSC 841ms. (DS = 95) y para TCSD 785ms. (DS = 90). La tasa promedio de aciertos de la TDL fue de 29, de la TCSC de 28,7 y de la TCSD de 28,675.
En la Tabla 3 pueden observarse los valores de Porcentaje de errores y Promedio de Tiempo de respuesta para las tres tareas discriminados según conceptos de alta y baja riqueza semántica y el resultado de la prueba t. La Figura 1 ilustra las diferencias entre ambos grupos de conceptos en los tiempos de respuesta para las tres tareas ya que es la variable que mostró diferencias significativas.


Como se observaron diferencias significativas únicamente en los tiempos de respuesta se continuaron los análisis sólo sobre esta variable. Se procedió al cálculo de un análisis de regresión lineal tomando como variable dependiente al tiempo de respuesta y como independiente a la NdA (tomando los valores como variable continua en este caso). Como se puede observar en la Tabla 4 hay un efecto del NdA sobre los tiempos de respuesta de las tres tareas. A su vez, si se miran los valores de r2 se infiere que el porcentaje de varianza explicado por esta variable es bajo, con lo cual se hace necesario incluir otras variables explicativas en el modelo.

A continuación se realizaron análisis de regresión por tarea incluyendo las variables Edad de Adquisición (EdA), Familiaridad (Manoiloff et al., 2010), Frecuencia Léxica, Imaginabilidad, Concreción (concreteness) (Martínez-Cuitiño, Barreyro, Wilson, y Jaichenco, 2015), Cantidad de Fonemas y Densidad (Vivas, et al., 2017). En la Tabla 5 se observan las correlaciones entre la variable dependiente y las independientes para las tres tareas.

Los resultados del análisis de regresión referido a la TDL se observan en la Tabla 6. En el modelo resultante (modelo 3) quedaron incluidas las variables NdA, EdA y Cantidad de Fonemas por ser las que tienen mayor contribución en la explicación de la varianza. Los valores de beta indican el sentido y la magnitud del efecto. Se puede ver que el NdA influyó en la velocidad de respuesta, pero tuvieron un mayor efecto la EdA y la Cantidad de Fonemas.
En el análisis de regresión para la TCSC quedaron incluidas las variables EdA y Densidad (Tabla 6). Se observó que a menor EdA menor el promedio de tiempo, mientras que a mayor Densidad de atributos del concepto también menor tiempo de respuesta. Dado que se hipotetizaba que el NdA tendría un efecto en esta tarea y no se esperaba observar un efecto de la Densidad, se realizó otro análisis para ver si había alguna asociación entre el grado de concreción (concreteness) de los conceptos y su Densidad que pudiera dar cuenta de la importancia de esta variable para esta tarea (ya que requiere determinar concreción (concreteness) del concepto). Efectivamente se encontró una fuerte correlación positiva entre Densidad y Concreción (concreteness) (r = 0,254; p<0,001).

En tercer lugar, como se ve en la Tabla 6, al igual que en la primera tarea, en TCSD se observó que a mayor NdA menor velocidad de respuesta. En este caso esta variable es la de mayor peso explicativo en el modelo (beta= -0,445) junto con Familiaridad. También se observó un efecto de la Imaginabilidad donde a mayor Imaginabilidad menor tiempo de respuesta.
En cuarto lugar, se compararon las tres tareas y se observó que la magnitud del efecto del NdA fue mayor para la TCSD (beta = -0,445) que para la TDL (beta = -0,230). A su vez, para la TDSD ingresa primero en el modelo, indicando que es la variable que explica mayor parte de la varianza de los datos, mientras que para la TDL ingresa más tarde. Finalmente, para TCSC no se observó un efecto significativo de esta variable con lo que quedó excluida del modelo estadístico.
Discusión
En esta investigación se propuso estudiar el efecto de la Riqueza semántica, medida mediante el NdA, en tareas de reconocimiento visual de palabras que requieran distintos niveles de procesamiento. Con respecto a la TDL, los resultados indican que a mayor NdA menor tiempo de respuesta, coincidiendo con lo reportado por otros autores (Grondin et al., 2009; Yap, 2012; Sajin y Connine, 2014). Como fue desarrollado previamente, es importante comentar que en la resolución de la TDL, si bien es una tarea principalmente léxica, intervienen diversos niveles de procesamiento. En este sentido, los datos dan soporte a la propuesta de Chen y Mirman (2012), quienes proponen que las conexiones entre los niveles son bidireccionales, indicando que existe una influencia del procesamiento semántico en el procesamiento de las formas y viceversa. Este modelo permite comprender la influencia de una variable semántica (la Riqueza semántica medida mediante el NdA) en una tarea léxica por medio de un mecanismo de retroalimentación del nivel semántico al léxico. Este mecanismo implica que los conceptos con mayor NdA tendrían mayor nivel de activación a nivel semántico generando mayor efecto, a su vez, sobre el nivel léxico (Balota, 1990).
Además, se observó un efecto de la EdA en esta tarea. Esta variable, que refiere al momento vital en el que los sujetos incorporan conceptos a su sistema semántico y lexical (Manoiloff, et al., 2010) y ha demostrado tener un efecto en tareas de este tipo (Alija y Cuetos, 2006; Brysbaert, Van Wijnendaele, y De Deyne, 2000). Esto reafirma la idea de que las palabras aprendidas más tempranamente estarían más disponibles en el lexicón mental que las adquiridas más tardíamente.
Otra variable que mostró un efecto significativo es la Cantidad de fonemas, lo cual era esperable dado que se requiere la lectura de la palabra para responder y esta variable está directamente relacionada con el tiempo que insume. Tal como proponen Yap y Pexman (2015) es esperable observar en estas tarea un efecto aditivo de variables semánticas y de cualidades de del estímulo dada la suposición de una interacción entre niveles.
En la segunda tarea, TDSC, los resultados obtenidos no corroboran la hipótesis inicial acerca de que tendría cierta influencia del NdA. Las variables que mostraron tener efectos en los tiempos de respuesta fueron EdA y Densidad (medida de la interrelación entre los atributos definidores del concepto). Es importante remarcar que esta última es una variable semántica que presenta una fuerte asociación con el número de atributos (véase Pexman et al., 2003). En trabajos previos realizados por Grondin et al. (2009) y Pexman et al. (2003) estos autores controlaron esta variable seleccionando conceptos de alto y bajo NdA pero con similares valores de densidad. Aún así, ellos encontraron efectos del NdA. En nuestro caso, no se observó dicho efecto. Los resultados obtenidos por Pexman y colaboradores proporcionan apoyo empírico a la idea de que la riqueza semántica de un concepto facilita el reconocimiento de la palabra, independientemente de la tarea que se esté estudiando. Nuestros resultados van en otro sentido, sugiriendo que esta variable no tendría tal peso en la TDSC. De acuerdo con los resultados del presente trabajo la Densidad tendría un efecto más fuerte en la decisión de la concreción (concreteness) de la palabra. A su vez, esta variable presenta una fuerte asociación con el grado de Concreción (concreteness) de los conceptos, lo cual explicaría por qué los de mayor valor de Densidad son clasificados más rápidamente.
Por otra parte, cabe hipotetizar que para poder determinar la concreción (concreteness) de un concepto no es necesario activar un gran número de atributos sino simplemente aquellos que indiquen si es un objeto que puede ser percibido por los sentidos o no. Probablemente, la activación de la imagen del objeto ya sea suficiente para determinar si es o no concreto. Este podría ser el motivo por el cual la cantidad de atributos no tenga mayor relevancia en esta tarea. Cabe recordar aquí que estamos comparando la velocidad de respuesta ante los conceptos concretos con alto y bajo NdA y no estamos comparando entre concretos y abstractos, donde probablemente, a su vez, los primeros cuenten con mayor riqueza que los segundos.
En tercera instancia, se observó un efecto significativo del NdA en la TCSD. Esta tarea exige un procesamiento de mayor demanda semántica para el sujeto, y por ende, un acceso obligatorio a los atributos. Para determinar si los conceptos presentados son seres vivos o no es necesario valorar si presentan propiedades de uno u otro grupo. Por lo tanto, se requiere identificar si respira o no, si tiene ciclo vital, si se reproduce, etc. Cabe esperar que a mayor cantidad de atributos presentes en su representación semántica (mayor NdA) habrá mayor información que permita ubicarlo en una u otra categoría. Si bien son escasos los estudios con esta tarea, un trabajo reciente mediante RMNf obtuvo resultados consistentes con los encontrados en el presente trabajo (Ferreira, Göbel, Hymers y Ellis, 2015). Los autores demostraron a su vez, mayor activación del giro angular izquierdo y el giro temporal medio anterior para las palabras con mayor riqueza.
Pensando en una hipótesis acerca del tipo de procesamiento cognitivo que probablemente esté detrás de la tarea es posible que la persona deba acceder a más de un tipo de atributo para estimar la pertenencia de un concepto al dominio de ser vivo o no-vivo. Si bien es probable que tengamos almacenada la información referida a la categoría taxonómica inmediata (por ej. es una planta), es probable que no tengamos almacenada la clasificación de vivo y no-vivo sino que hagamos una inferencia a partir de sus propiedades al momento de realizar la tarea (ej. tener un ciclo vital, respirar, requerir alimento). Con lo cual, para categorizarlo debemos valorar sus propiedades para dar cuenta de su cualidad o no de ser viviente. Es decir, hay atributos de mayor relevancia para establecer una categorización de este tipo, pero a su vez, estos atributos suelen estar altamente correlacionados con otros (esto está particularmente estudiado en el caso de los animales y frutas y verduras) (Moss, Tyler y Taylor, 2007). Lo que explica que a mayor riqueza semántica más fácil la tarea de categorización. Sin embargo, también hay modelos que consideran que existen algunas categorías innatas (Caramazza y Shelton 1998), particularmente aquellas que tuvieron una función adaptativa, como animados e inanimados. Siguiendo a esta teoría no debería observarse un efecto de la riqueza semántica en el sentido recién mencionado dado que no sería necesario valorar un cúmulo de atributos. Nuestros datos muestran un efecto de esta variable en la TDSD con lo cual no irían a favor de esta hipótesis.
En la tarea de decisión por dominio también se observaron efectos significativos de la Familiaridad y de la Imaginabilidad. Respecto de esta última variable se encontró que a mayor Imaginabilidad menor tiempo de respuesta, lo cual es consistente con trabajos previos (Yap y Pexman, 2015). Respecto de la Familiaridad se observó que a mayor valor en esta variable mayor tiempo de respuesta, lo cual es contraintuitivo. Cabría esperar que a mayor familiaridad menor tiempo de respuesta (tal como reportan Ferreira et al., 2015). Sin embargo, si se observan las correlaciones de la Tabla 3 no se registra una asociación significativa entre ambas variables (Familiaridad y TR) en esta tarea, con lo cual cabe suponer que el efecto se debió a la interacción de la familiaridad con alguna otra variable psicolingüística en mayor medida que a su relación con el tiempo de respuesta.
En cuarta instancia, se verifica la hipótesis inicial que establecía que la TCSD tendría un efecto más fuerte que las otras dos tareas. Siguiendo el modelo propuesto por Chen y Mirman (2012) que plantea la existencia de diferentes niveles de procesamiento con influencia mutua, cabe suponer que esta tarea tiene una mayor influencia de las variables semánticas que la tarea de decisión léxica dado que la decisión de la pertenencia a una categoría requiere reconocer si el concepto posee ciertos atributos definidores de dicha categoría, con lo cual se requiere una respuesta desde el sistema semántico. Por este motivo la variable NdA tendría un mayor efecto. Sin embargo, también se demuestra que el desempeño en estas tareas está multideterminado ya que recibe la influencia de variables de distintos niveles de procesamiento, aunque ese efecto esté ponderado en función del tipo de tarea.
Conclusiones
Los resultados obtenidos aportan evidencia de que existe un efecto de la Riqueza semántica, medida mediante el NdA, en la resolución de las tareas de Decisión Léxica y de Categorización Semántica por Dominio. A mayor NdA de los conceptos es menor el tiempo de respuesta. Este trabajo es el primero en analizar el efecto de esta variable a partir de una medida colectada en base a una muestra hispanoparlante y verificar parcialmente los resultados obtenidos en hablantes de otras lenguas. Con respecto a este punto si bien hay trabajos que han reportado que el núcleo semántico (conformado por los atributos de mayor importancia) de los conceptos es compartido entre distintas lenguas (Kremer y Baroni, 2011) también hemos encontrado en un estudio aún no publicado de nuestro laboratorio que hay diferencias entre lenguas en los valores de riqueza semántica medida mediante número de atributos (entre inglés, alemán, español e italiano). De hecho con una simple mirada a las normas en inglés de McRae Cree, Seidenberg, y McNorgan (2005) y en español de Vivas et al. (2017) se puede observar que los valores de las normas del primero son sustancialmente más altos que los del segundo en lo que respecta a esta variable (llamada en esas bases 5_feat_no_tax). Entendemos que esto justifica el uso de normas propias de habla hispana y permite suponer que puede haber diferencias en la influencia de esta variable en las tareas seleccionadas. No hay certezas aún acerca de la causa de estas diferencias pero nuestras hipótesis actuales apuntan hacia variables motivacionales en la ejecución de la tarea (ej. obtención de crédito académico, reconocimiento por parte del docente o pago monetario por la participación) que difirieron sustancialmente entre ambas lenguas. Sin embargo, sería esperable que el tipo de efecto observado del NdA sobre las tareas sea similar al hallado en otras lenguas dado que se asume un procesamiento cognitivo similar. Es decir, a pesar de que los valores absolutos de NdA difieren entre lenguas es esperable que sus efectos en ciertas tareas se observen de igual manera. En el presente trabajo arribamos a resultados coincidentes con los de habla inglesa para TDL y TDSD pero no para TDSC.
Por otra parte, es relevante destacar que los datos mostraron efectos diferenciales para las tres tareas sugiriendo que el efecto de NdA no es unívoco. En este sentido, en consonancia con el modelo de Chen y Mirman (2012) habría distintos niveles en el procesamiento léxico-semántico, ejerciendo influencias entre sí. Dependiendo de la complejidad de la tarea y el tipo de información que requieran el efecto de la NdA será diferente. Por eso, lo novedoso de esta investigación ha sido comprobar el efecto de NdA en tareas donde la demanda de procesamiento varía (de léxico a semántico) y particularmente en una tarea de categorización por dominio, aportando evidencia de un mayor efecto en tareas semánticas que requieren para su resolución el acceso a los atributos.
Sin embargo, según lo hipotetizado, el efecto de NdA debería haberse presentado también en la TDSC. Una futura línea de investigación debería incluir palabras con mayor diversidad de concreción (concreteness) para analizar si allí aparece un efecto diferencial del NdA, incluyendo también otras medidas de riqueza semántica (como número de significados asociados, dispersión de contexto o número de vecinos). Por otra parte, sería interesante estudiar cuáles son los atributos nucleares de los conceptos en cuestión, su tipo y cantidad, para poder identificar cuáles son los atributos que al estar presentes en el núcleo de la representación conceptual permiten determinar la concreción (concreteness) de un concepto con mayor velocidad.
Una de las limitaciones que cabe mencionar del presente estudio es el desbalance de género de la muestra seleccionada. Al incluir estudiantes de la carrera de Psicología, quedó reflejada una fuerte presencia femenina en dicha carrera característica de nuestro país. Sería interesante en trabajos futuros poder contar con muestras equiparables de ambos géneros para poder establecer comparaciones en su desempeño (particularmente en cuanto a la respuesta ante conceptos de distintos dominios semánticos).





Referencias
1. Algarabel, S. (1996). Índices de interés psicolingüístico de 1.917 palabras castellanas. Cognitiva, 8, 43-88. https://doi.org/10.1174/021435596321235298. [ Links ]
2. Alija, M. y Cuetos, F. (2006). Efectos de las variables léxico-semánticas en el reconocimiento visual. Psicothema, 18, 485-491. [ Links ]
3. Aron, A. y Aron, E.N. (2001). Estadística para psicología. Segunda edición. Buenos Aires: Pearson Education. [ Links ]
4. Balota, D. A. (1990). The role of meaning in word recognition. En D. A. Balota, G. B. Flores d'Arcais, y K. Rayner (Eds.), Comprehension processes in reading (pp. 9-32). Hillsdale, NJ: Lawrence Erlbaum Associates. [ Links ]
5. Brysbaert, M., Van Wijnendaele, I., y De Deyne, S. (2000). Age-of-acquisition of words is a significant variable in semantic tasks. Acta Psychologica, 104, 215-226. https://doi.org/10.1016/S0001-6918(00)00021-4. [ Links ]
6. Caramazza, A. y Shelton, J.R. (1998). Domain specific knowledge systems in the brain: The animate-inanimate distinction. Journal of Cognitive Neuroscience, 10, 1-34. https://doi.org/10.1162/089892998563752. [ Links ]
7. Chen, Q. y Mirman, D. (2012). Competition and cooperation among similar representations: toward a unified account of facilitative and inhibitory effects of lexical neighbors. Psychological Review, 119 (2), 417-430. https://doi.org/10.1037/a0027175. [ Links ]
8. Cycowicz, Y. M., Friedman, D., Rothstein, M., y Snodgrass, J. G. (1997). Picture naming by young children: Norms for name agreement, familiarity, and visual complexity. Journal of Experimental Child Psychology, 65, 171-237. https://doi.org/10.1006/jecp.1996.2356. [ Links ]
9. Declaración de Helsinki de la AMM. Principios éticos para las investigaciones médicas en seres humanos. 64th Asamblea Geneal, Fortaleza, Brasil, octubre 2013. [ Links ]
10. Ferreira, R. A., Göbel, S. M., Hymers, M., y Ellis, A. W. (2015). The neural correlates of semantic richness: Evidence from an fMRI study of word learning. Brain and Language, 143, 69-80. https://doi.org/10.1016/j.bandl.2015.02.005. [ Links ]
11. Grondin, R., Lupker S., y McRae K. (2009). Shared features dominate semantic richness effects for concrete concepts. Journal of Memory and Language, 60, 1-19. https://doi.org/10.1016/j.jml.2008.09.001. [ Links ]
12. Hino, Y., Pexman, P.M., y Lupker, S.J. (2006). Ambiguity and relatedness effects in semantic tasks: Are they due to semantic coding? Journal of Memory and Language, 55, 247-273. https://doi.org/10.1016/j.jml.2006.04.001. [ Links ]
13. Kremer, G. y Baroni, M. (2011). A set of semantic norms for German and Italian. Behavior Research Methods, 43, 97-109. https://doi.org/10.3758/s13428-010-0028-x. [ Links ]
14. Manoiloff, L., Artstein, M., Canavoso, M., Fernández, L., y Segui, J. (2010). Expanded norms for 400 experimental pictures in an Argentinean Spanishspeaking population. Behavior Research Methods, 42, 452-460. https://doi.org/10.3758/BRM.42.2.452. [ Links ]
15. Martínez-Cuitiño, M.; Barreyro, J.P.; Wilson, M. y Jaichenco, V. (2015). Nuevas normas semánticas y de tiempos de latencia para un set de 400 dibujos en español. Interdisciplinaria, 32, 289-305. [ Links ]
16. McRae, K., Cree, G. S., Seidenberg, M. S., y McNorgan, C. (2005). Semantic feature production norms for a large set of living and nonliving things. Behavior Research Methods, 37(4), 547-559. https://doi.org/10.3758/BF03192726. [ Links ]
17. Moss, H.E., Tyler, L.K., y Taylor, K.I. (2007). Conceptual structure. En: G. Gaskell (Ed.), Oxford Handbook of Psycholinguistics (pp. 217-234). Oxford, UK: Oxford University Press. https://doi.org/10.1093/oxfordhb/9780198568971.013.0013. [ Links ]
18. Pexman, P., Lupker S. y Hino, (2002). The impact of feedback semantics in visual Word recognition: Number-of-features effects in lexical decision and naming tasks. Psychonomic Bulletin & Review, 9, 542-549. https://doi.org/10.3758/BF03196311. [ Links ]
19. Pexman, P., Holyk G., y Monfiels M. (2003). Number-of-features effects and semantic processing. Memory & Cognition, 31, 842-855. https://doi.org/10.3758/BF03196439. [ Links ]
20. Pexman, P., Hargreaves I., Siakaluk P., Bodner G., y Pope J. (2008). There are many ways to be rich: Effects of three measures of semantic richness on visual word recognition. Psychonomic Bulletin & Review, 15, 161-167. https://doi.org/10.3758/PBR.15.1.161. [ Links ]
21. Sajin, S. y Connine C. (2014). Semantic richness: The role of semantic features in processing spoken words. Journal of Memory and Language, 70, 13-35. https://doi.org/10.1016/j.jml.2013.09.006. [ Links ]
22. Vivas, J., Vivas, L., Comesaña, A., Coni. A.G., Vorano, A. (2017). Spanish Semantic Feature Production Norms for 400 concrete concepts. Behavior Research Methods, 49, 1095-1106. https://doi.org/10.3758/s13428-016-0777-2. [ Links ]
23. Yap, M., Tan, S., Pexman P. y Hargreaves, I. (2011). Is more always better? Effects of semantic richness on lexical decision, speeded pronunciation, and semantic classification. Psychonomic Bulletin & Review, 18, 742-750. https://doi.org/10.3758/s13423-011-0092-y. [ Links ]
24. Yap, M. y Pexman, P. (2015). Semantic richness effect in lexical decision: the role of feedback. Memory & Cognition, 43, 1148-1167. https://doi.org/10.3758/s13421-015-0536-0. [ Links ]
25. Yap, M., Pexman P., Wellsby M., Hargreaves I. y Huff M. (2012). An abundance of richess: cross-task comparisons of semantic richness effects in visual word recognition. Frontiers in Human Neuroscience, 6, 1-10. https://doi.org/10.3389/fnhum.2012.00072. [ Links ]
![]() Dirección para correspondencia:
Dirección para correspondencia:
Leticia Vivas.
Facultad de Psicología,
Universidad Nacional de Mar del Plata.
Diagonal J. B. Alberdi 2695,
7600 Mar del Plata,
Buenos Aires, Argentina.
E-mail: lvivas@mdp.edu.ar.
E-mail del coautor: fragapanemauro@gmail.com.
Recibido: 24 de abril de 2016
Revisado: 14 de febrero de 2017
Aceptado: 28 de febrero de 2017

