










Mi SciELO
 Servicios personalizados
Servicios personalizadosServicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares en
SciELO
Similares en
SciELO -
 Similares en Google
Similares en Google
Compartir

 Permalink
PermalinkRevista Española de Salud Pública
versión On-line ISSN 2173-9110versión impresa ISSN 1135-5727
Rev. Esp. Salud Publica vol.88 no.2 Madrid mar./abr. 2014
https://dx.doi.org/10.4321/S1135-57272014000200007
ORIGINAL
Desarrollo de un modelo de predicción de riesgo de hospitalizaciones no programadas en el País Vasco(*)
Development of a Predictive Risk Model for Unplanned Admissions in the Basque Country
Juan F. Orueta Mendia (1,3), Arturo García-Álvarez (2), Edurne Alonso-Morán (3) y Roberto Nuño-Solinis (3)
(1) Centro de Salud de Astrabudua.Osakidetza (Servicio Vasco de Salud). Erandio. Bizkaia. España.
(2) Kronikgune (Centro de Investigación en Cronicidad).
(3) O+berri. Instituto Vasco de Innovación Sanitaria. Sondika. Bizkaia. España.
Los autores declaran no presentar ningún conflicto de intereses.
(*) Este trabajo forma parte de un estudio financiado por Kronikgune (Centro de Investigación en Cronicidad) mediante una beca (KRONIK011/035).
Dirección para correspondencia
RESUMEN
Fundamentos: La hospitalizaciones son eventos indeseables que en ocasiones pueden ser evitados mediante intervenciones proactivas. El objetivo del estudio es determinar la capacidad de modelos basados en Adjusted Clinical Groups (ACGs) en nuestro medio para identificar a los pacientes que presentarán ingresos no programados en los meses siguientes a su clasificación, tanto en la población general como en subpoblaciones de enfermos crónicos (diabetes mellitus, enfermedad pulmonar obstructiva crónica e insuficiencia cardiaca).
Métodos: Estudio transversal que analizó información de un periodo de 2 años, de todos los residentes en Euskadi mayores de 14 años de edad (n=1.964.337). Los datos del primer año (demográficos, índice de privación socioeconómica, diagnósticos, prescripciones, procedimientos, ingresos y otros contactos con el servicio de salud) sirvieron para construir las variables independientes. Las hospitalizaciones del segundo año, las dependientes. Se empleó el área bajo la curva ROC (AUC) para evaluar la capacidad de los modelos en discriminar a los pacientes con hospitalizaciones y se calculó el valor predictivo positivo y la sensibilidad en diferentes puntos de corte.
Resultados: En la población general, los modelos para predecir ingresos a los 6 y 12 meses así como hospitalizaciones prolongadas mostraron un comportamiento bueno (AUC>0,8), mientras que fue aceptable (AUC 0,7-0,8) en los grupos de pacientes crónicos.
Conclusiones: Un sistema de estratificación de riesgo de ingresos, basado en ACGs resulta válido y aplicable en nuestro medio. Estos modelos permiten clasificar a los pacientes en una escala de mayor a menor riesgo, lo cual hace posible la aplicación de las intervenciones preventivas más costosas solamente a un pequeño subgrupo de pacientes, mientras que otras menos intensivas pueden proporcionarse a grupos más amplios.
Palabras clave: Ajuste de riesgo. Modelos predictivos. Hospitalizaciones. Enfermedades crónicas. Sistemas de información sanitaria.
ABSTRACT
Background: Hospitalizations are undesirable events that can be avoided to some degree through proactive interventions. The objective of this study is to determine the capability of models based on Adjusted Clinical Groups (ACG), in our milieu, to identify patients who will present unplanned admissions in the following months to their classification, in both the general population and in subpopulations of chronically ill patients (diabetes mellitus, chronic obstructive pulmonary disease and heart failure).
Methods: Cross-sectional study which analyzes data from a two year period, of all residents over 14 years old in the Basque Country (N = 1,964,337). Data from the first year (demographic, deprivation index, diagnoses, prescriptions, procedures, admissions and other contacts with the health service) were used to construct the independent variables; hospitalizations of the second year, the dependent ones. We used the area under the ROC curve (AUC) to evaluate the capability of the models to discriminate patients with hospitalizations and calculated the positive predictive value and sensitivity of different cutoffs.
Results: In the general population, models for predicting admission at 6 and 12 months, as well as long-term hospitalizations showed a good performance (AUC> 0.8), while it was acceptable (AUC 0.7 to 0.8) in the groups of chronic patients.
Conclusions: A hospitalization risk stratification system, based on ACG, is valid and applicable in our milieu. These models allow classifying the patients on a scale of high to low risk, which makes possible the implementation of the most expensive preventive interventions to only a small subset of patients, while other less intensive ones can be provided to larger groups.
Key words: Risk adjustment.Predictive modeling. Hospitalizations. Chronic diseases. Health information systems.
Introducción
La predicción de las hospitalizaciones y la identificación de las personas que requerirán ingresos en el futuro es motivo de interés para las organizaciones sanitarias por diversas razones. En primer lugar, porque son eventos indeseables para los pacientes y sus familiares. En segundo lugar, porque las hospitalizaciones resultan especialmente costosas para los sistemas de salud, que deben dedicar a ellas una parte sustancial de su presupuesto. Y por último, porque existen evidencias de que en determinados casos pueden ser evitadas mediante la puesta en marcha de intervenciones oportunas1.
Por otra parte, una proporción muy importante de los ingresos hospitalarios se concentran en unas pocas personas. Así, en el País Vasco en el año 2011, el 1% de la población requirió 62.757 hospitalizaciones (que supusieron el 29,5% del número total y su coste alcanzó el 46,7% del generado por todos los ingresos en hospitales públicos de la comuidad autónoma). La identificación previa de las personas que necesitarán ser ingresadas en un futuro próximo, especialmente las que requerirán hospitalizaciones prolongadas o repetidas, es un elemento fundamental para la realización de programas proactivos, como los de gestión de casos u otros.
En España2, y en otros países, principalmente Estados Unidos3 y el Reino Unido4, la mayor parte de los modelos de predicción de ingresos se han dirigido específicamente a las rehospitalizaciones. Sin embargo, la identificación de las personas en riesgo pero que todavía no han sido previamente ingresadas, ofrece oportunidades de intervención más amplias y puede permitir actuaciones más precoces que eviten un mayor deterioro en este segmento de la población. Los modelos predictivos de ajuste de riesgo son instrumentos que fueron diseñados para clasificar a las personas en función de la cantidad de cuidados sanitarios que requerirán en el futuro, y pueden emplearse como método de cribado poblacional para identificar a las personas en mayor riesgo de hospitalización5.
Un aspecto a destacar es que el objetivo final de estos programas no consiste en la correcta predicción de qué pacientes serán ingresados, sino la selección del subgrupo formado por las personas que con mayor probabilidad obtendrán buenos resultados, como, por ejemplo, los que presentan determinados problemas de salud susceptibles de ser tratados con las citadas actividades proactivas6. En el País Vasco se están desarrollando intervenciones en ese sentido, cuyo fin es avanzar hacia un sistema sanitario más integrado y sostenible, que proporcione cuidados de mayor calidad a la población7. Una de las iniciativas fue la puesta en marcha del Programa de Estratificación Poblacional8, para el cual los ciudadanos son clasificados anualmente aplicando el sistema de case-mix Adjusted Clinical Groups (ACGs) de la Universidad Johns Hopkins9 y otras variables.
El objetivo de este estudio fue determinar la capacidad de modelos basados en ACGs para identificar a pacientes que presentarán ingresos no programados en los periodos de 6 y 12 meses siguientes a su clasificación, así como aquellos que requerirán hospitalizaciones prolongadas. Un segundo objetivo es comprobar la validez de dichos modelos predictivos en determinadas subpoblaciones de enfermos con algunas enfermedades crónicas, que se consideran especialmente sensibles a una atención ambulatoria oportuna para evitar hospitalizaciones.
Material y métodos
Este estudio transversal fue llevado a cabo en el servicio vasco de salud, Osakidetza. La población de estudio estuvo formada por todas las personas de edad superior a 14 años que contaban con cobertura sanitaria por Osakidetza el 1 de septiembre de 2008. El periodo de estudio corresponde a dos intervalos consecutivos de 12 meses. Los datos del primer año (de 1/09/2007 a 31/08/2008) se utilizaron para construir las variables explicativas, mientras que los del segundo año (de 1/09/2008 a 31/08/2009) para las variables respuesta. Se estableció un periodo mínimo de seguimiento en el primer año, incluyéndose en el estudio solamente a las personas que dispusieron de aseguramiento público durante al menos 6 meses, independientemente de que hubieran realizado una visita o tenido cualquier tipo de contacto con los servicios de Osakidetza (n=1.973.971). De ellos, 28.182 personas no completaron el segundo año, por defunción (n =18.548) o traslado fuera de la comunidad autónoma y otras causas (n= 9.634). Se consideró sujetos de estudio a los ciudadanos que fallecieron en el segundo año, mientras que se dio de baja a los excluidos por otras razones. Por tanto, la población definitiva se compuso de 1.964.337 personas.
El estudio recibió aprobación del Comité ético de investigación clínica de Euskadi (CEIC-E). Se empleó un identificador opaco, para garantizar la confidencialidad de datos personales.
Fuente de información: Se empleó la base de datos del Programa de Estratificación Poblacional del País Vasco (PREST), la cual incluye registros individualizados de los ciudadanos que disponen de cobertura sanitaria pública por Osakidetza, esto es, la práctica totalidad de los residentes en la comunidad autónoma. Engloba información procedente de atención primaria, especializada y otras bases de datos del Departamento de Salud, conteniendo información demográfica (edad, sexo y área censal de residencia), códigos CIE-9-MC de todos los diagnósticos (de altas de hospital y de motivos de consulta al médico de primaria y a los servicios de urgencias), procedimientos relevantes, fármacos prescritos, contactos con los servicios de salud y coste de los mismos. Como proxy de la posición socioeconómica individual, se empleó el índice de privación de área censal de residencia elaborado por el proyecto MEDEA10 categorizado en quintiles. PREST no contiene más información que la registrada de forma rutinaria en las historias clínicas. Una descripción más detallada de esta base de datos puede obtenerse en otra publicación8.
Sistema de clasificación de pacientes: Adjusted Clinical Groups predictive modelling (ACG-PM)9: ACGs es un sistema de case-mix diseñado por investigadores de la Universidad Johns Hopkins. Para sus modelos predictivos emplea como variables explicativas información procedente de diagnósticos, prescripciones, algunos procedimientos relevantes, utilización de servicios sanitarios y su coste en el año previo. Para el presente estudio se empleó la versión 9.0 de ACG-PM.
Los ACGs son 94 categorías autoexcluyentes en las cuales se clasifica a cada persona en función de su edad, sexo y diagnósticos que se le hayan realizado durante los últimos 12 meses. Los diagnósticos son clasificados también en otros 3 modos distintos: en 264 Expanded Diagnosis Clusters (EDCs) en función de las características clínicas de este problema de salud, HOSDOM, que identifica patologías con alto riesgo de hospitalización en el año siguiente y un marcador de fragilidad.
Por otra parte, los fármacos se clasifican en 69 Rx-defined Morbidity Groups (Rx-MGs), según la patología que puede deducirse a partir de su prescripción. Un marcador de polifarmacia identifica a los pacientes que en un año han recibido más de 12 fármacos distintos.
No todos estos grupos son incluidos como variables en los modelos predictivos. El modelo final incorpora 140 procedentes de diagnósticos (34 categorías para ACGs, 101 EDCs, 4 categorías para el número de HOSDOM y el marcador de fragilidad) y 65 para prescripciones (64 Rx-MGs y polifarmacia). A ellos se agregan 9 variables demográficas (sexo, más 8 grupos de edad), 20 referentes a coste sanitario previo total y en farmacia (generados a partir de la agrupación de los pacientes en bandas de percentiles) y 16 correspondientes a utilización de recursos (inclusión en programa de diálisis crónica, agrupaciones de número de hospitalizaciones, visitas a urgencias y a consultas externas).
El sistema ofrece predicciones de distintos riesgos de ingreso: en hospital de agudos en los siguientes 6 y 12 meses, en unidad de cuidados intensivos, estancia prologada en hospital de agudos (más de 12 días ingresado como consecuencia de uno o más ingresos, durante los siguientes 12 meses) y hospitalización como consecuencia de una lesión traumática.
Variables de estudio y modelos estadísticos: Se construyeron modelos de regresión logística, empleando 3 variables respuesta diferentes: ingreso no programado en los 6 meses siguientes a la clasificación de cada persona, ingreso en los 12 meses y hospitalización prolongada. De dichas hospitalizaciones se excluyeron las generadas por causa obstétrica o lesiones traumáticas, pues nuestro objetivo fundamental era el diseño de un modelo para la identificación de pacientes (principalmente enfermos crónicos y pluripatológicos) que puedan beneficiarse de programas de gestión de casos.
Se emplearon dos conjuntos de variables independientes:
1.- Las predicciones (out of the box) que ofrece directamente el software ACGs. Se basan en la calibración de los modelos realizada por los diseñadores del case-mix en poblaciones americanas.
2.- Recalibración de los modelos utilizando el conjunto completo de las 250 variables que emplea el agrupador más el índice de privación del área de residencia.
Para evitar problemas de sobreajuste se realizó validación cruzada, dividiéndose a la población en dos mitades de forma aleatoria. Al evaluar y comparar los modelos se empleó el área bajo la curva ROC (AUC)11 calculando los intervalos de confianza mediante el método de bootstrapping, utilizando 1.000 submuestreos. Además, se calculó el valor predictivo positivo (VPP) y la sensibilidad en diferentes puntos de corte.
Tales análisis se repitieron en la población total (1.964.337) y en tres subpoblaciones de enfermos crónicos, identificados a partir de las agrupaciones de diagnósticos y prescripciones del sistema ACG: diabetes mellitus (100.342), insuficiencia cardiaca (64.191) y enfermedad pulmonar obstructiva crónica (29.516). En estas tres subpoblaciones se compararon las predicciones de los valores out-of-the-box con las de dos recalibraciones locales: una obtenida aplicando a cada subpoblación los coeficientes de regresión calculados para toda la población de País Vasco y otra resultante de realizar una nueva calibración (incluyendo validación cruzada) que empleó exclusivamente los datos de cada subpoblación.
Los análisis se realizaron utilizando el programa SAS (versión 9.2)12 y las funciones de la librería ROCR13 del entorno de programación R14.
Cálculo de los promedios de coste observado en el año 2 por hospitalizaciones para los pacientes con mayor riesgo esperado: A partir de las predicción de hospitalizaciones a 12 meses (con el modelo recalibrado localmente) se clasificó en percentiles a toda la población de estudio en función de la probabilidad de que se produjera dicho evento. Se emplearon diferentes puntos de corte y, de este modo, consideramos como "alto riesgo" a las personas cuyo percentil superaba dicho umbral. De este modo, se establecieron 6 bandas de riesgo que no son autoexcluyentes y van desde la más amplia, que incluye al 10% de toda la población (>Percentil 90%) hasta la más restrictiva (>Percentil 99,9%).
Posteriormente se estimaron los costes de las hospitalizaciones observadas en el año 2 a partir de la clasificación de todos los ingresos en Grupos Relacionados por el Diagnóstico (GRD) y sus valores estandarizados. Se calcularon los promedios de coste de hospitalización durante el año 2 para los grupos de pacientes incluidos en cada una de las bandas de riesgo antes citadas.
Resultados
En la tabla 1 se muestran algunas características de la población estudiada. El 51% eran mujeres y el porcentaje de mayores de 65 años fue 22%. Casi el 79% de las personas tuvo algún contacto con los servicios de salud de Osakidetza en el primer año y los promedios por paciente de visitas a consultas, urgencias de hospital e ingresos (por causas diferentes a las obstétricas y traumáticas) fueron, respetivamente: 6,17; 0,26 y 0,08.

Durante el segundo año, el 2,97% de las personas requirió una o más hospitalizaciones no programadas durante los primeros 6 meses, más del 5% a lo largo de los 12 meses y el 1,4% de la población estuvo ingresado durante al menos 12 días en dicho periodo. De ellos, solo una minoría lo había estado también el año previo. Es decir, de los 101.384 pacientes con ingresos en el año 2, 75.093 (74%) estuvieron libres de ellos en el año 1, incluso de los 27.758 con estancias prolongadas en el segundo año 17.797 (64%) no presentaron ninguna hospitalización durante el primero. Los modelos mostraron una buena capacidad para discriminar a los pacientes que presentarían hospitalizaciones (tabla 2) alcanzando valores de AUC que oscilaron entre 0,796 y 0,870. Como cabría esperar, los modelos recalibrados con nuestros datos mostraron valores más altos (0,823 para predicción de hospitalización en 6 meses; 0,809 en 12 meses y 0,870 de hospitalización prolongada) que los que ofrece por defecto el software del sistema ACGs (0,811; 0,796 y 0,855 respectivamente). Observando los VPP y la sensibilidad, los modelos que presentan unos resultados mejores son los de pacientes ingresados en 12 meses: así, por ejemplo, identificando al 1% de la población con una predicción de riesgo más alta, más del 50% de las personas seleccionadas necesitarán al menos un ingreso y en este grupo estarán incluidos casi el 10% de las personas que serán hospitalizadas, mientras que seleccionando al 5% de la población con mayor riesgo, la sensibilidad y VPP son superiores al 30%.

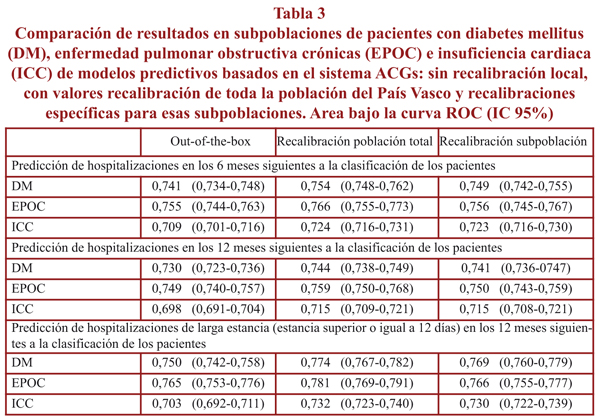
Como se puede comprobar en la tabla 3, los valores de AUC para las subpoblaciones de DM, EPOC e ICC son ligeramente más bajos que los de la población total (por ejemplo, para predicción de hospitalizaciones a 12 meses, 0,744 en diabetes; 0,759 en EPOC y 0,715 en insuficiencia cardiaca), y la realización de modelos que emplearon estimadores específicos de esa poblaciones no supusieron ninguna ventaja sobre el uso de los estimadores de la población general (respectivamente: 0,741; 0,750; 0,715).
Los promedios de coste observados en hospitalizaciones para los pacientes de diferentes bandas de riesgo se presentan en la tabla 4. Se observa que los grupos con mayor riesgo supusieron un mayor coste. Así, mientras que los pacientes que en función de su predicción se encontraron por encima del percentil 90 de riesgo, requirieron en promedio 2.181,9 € en la atención hospitalaria de los 12 meses posteriores, los que quedaron por encima del P99,9 consumieron 10.691,3 €. Este mismo gradiente se repitió en las supoblaciones de enfermos crónicos, en las que los costes oscilaron entre 5.841,9 y 15.849,1 (DM); 9508,0 y 12.730,3 (EPOC); 8379,1 y 14.373,4 (ICC).

Discusión
El sistema de predicción de riesgo de hospitalizaciones en el País Vasco, basado en la clasificación de la población mediante ACGs con la adición de variables socioeconómicas (índice de privación del área de residencia), muestra un comportamiento adecuado. El AUC es el método empleado habitualmente para evaluar la capacidad predictiva de este tipo de modelos estadísticos. Un AUC de 0,5 indicaría que la capacidad del modelo no es mejor que la que se obtendría por simple azar, mientras que un valor de 1 supondría que la sensibilidad y especificidad son óptimas. Con frecuencia se considera que un modelo alcanza una capacidad discriminativa aceptable si sus cifras de AUC están entre 0,7 - 0,8 y es buena si supera el valor de 0,83. Según este criterio, los resultados descritos resultan satisfactorios en las predicciones para la población general y aceptables para los subgrupos de pacientes afectos de patologías crónicas (diabetes mellitus, enfermedad pulmonar obstructiva crónica e insuficiencia cardiaca).
También resultan suficientes los valores de VPP y sensibilidad que ofrecen. Aunque distan de ser perfectos, estos modelos permiten clasificar a los pacientes según una escala de mayor a menor riesgo, la cual se asocia con un gradiente de número y coste de hospitalizaciones3,15. Este hecho hace posible la aplicación de las intervenciones más costosas a solamente un pequeño subgrupo de pacientes, mientras que otras menos intensivas puede proporcionarse a grupos más amplios. La comparación del coste de tales actividades, con el previsible ahorro que pueda conseguirse, permite hacer una proyección sobre su coste-efectividad y servirá de ayuda a la toma de decisiones sobre su implantación.
Nuestro estudio presenta algunas limitaciones. En primer lugar, los datos analizados proceden de los registrados en los sistemas de información sanitaria del País Vasco de forma habitual y, como sucede siempre que se recurre al empleo de bases de datos administrativas o anotaciones de las historias clínicas informatizadas, pueden contener algunos registros incompletos o inexactos16. En cualquier caso, si bien la calidad de la información puede afectar a los resultados, nuestra base de datos se alimenta de registros de hospitales, atención especializada y primaria, cuyo empleo complementario puede paliar algunas de estas deficiencias17. Por otra parte, si bien en un sistema de salud como el nuestro, que proporciona asistencia universal y financiada por impuestos, existen menos barreras de acceso que en otros, en la medida que determinados subgrupos tengan menor accesibilidad, sus necesidades de atención quedarán peor registradas. Por último, la variable socioeconómica empleada (índice de privación) puede disminuir la contribución individual de las características socioeconómicas,dado su carácter ecológico.
Hasta la fecha se han descrito diversos sistemas para predicción de hospitalizaciones. Muchos de ellos combinan variables demográficas, diagnósticos e ingresos previos18-19. En algunos casos añaden información relativa a prescripciones5, datos de laboratorio20, factores de riesgo y factores socioeconómicos21. Los modelos basados exclusivamente en el número previo de hospitalizaciones tienen una escasa validez, por el fenómeno de regresión a la media22. Así mismo, la capacidad de los clínicos para identificar correctamente a los pacientes que volverán a ser ingresados resulta muy inferior a la de los modelos estadísticos23. También se han estudiado modelos muy simples que incluyen solamente el número de diagnósticos o fármacos como únicas variables para medir la morbilidad24. Sin embargo, independientemente de su menor capacidad explicativa, su utilidad se verá limitada, pues no ofrecen información clínica suficiente.
Una exigencia para la puesta en marcha de intervenciones sanitarias es que beneficien a toda la población en riesgo. Un modelo predictivo que no tenga en cuenta variables socioeconómicas puede provocar que las necesidades de los grupos más desfavorecidos se vean peor reflejadas y generar una sutil discriminación contra ellos en cuanto a su inclusión en programas de salud25. Por ese motivo, en nuestro modelo predictivo se emplea el índice de privación.
Además de los factores citados existen otros que también condicionan el riesgo de ingreso. Algunos tienen relación con las personas (como su grado de apoyo social, acceso a los servicios sanitarios o estado funcional) o con las organizaciones sanitarias (entre otros, coordinación de la atención o disponibilidad de camas de hospital)3. Aunque la inclusión de tal información pudiera mejorar la capacidad predictiva de los modelos, la aplicabilidad en el mundo real se verá condicionada por la disponibilidad de tales datos, que habitualmente no son registrados5,21.
Nuestro estudio ha permitido comprobar la validez de un sistema de predicción de riesgo de ingresos que resulta aplicable en nuestro medio, tanto en población general como en pacientes crónicos. Sin embargo, aunque tales modelos pueden resultar aptos para la identificación de pacientes candidatos a beneficiarse de programas proactivos, son necesarias nuevas investigaciones que evalúen la utilidad de la incorporación de nuevas variables3,26 y el desarrollo de modelos dirigidos específicamente a la discriminación de hospitalizaciones evitables6.
Agradecimientos
Los autores agradecen a Gonzalo López Arbeloa (Organización Central de Osakidetza) su ayuda en la obtención de datos para este estudio.
Al equipo del proyecto MEDEA del País Vasco, por calcular el índice de privación y aportar los datos del índice, y en especial a Montse Calvo, por el trabajo de geocodificación de los datos.
Bibliografía
1. Lewis G, Curry N, Bardsley M. Choosing a predictive risk model: a guide for commissioners in England. London: The Nuffield Trust; 2011. [ Links ]
2. López-Aguilà S, Contel JC, Farré J, Campuzano JL, Rajmil L. Predictive model for emergency hospital admission and 6-month readmission. Am J Manag Care. 2011; 17(9): e348-57. [ Links ]
3. Kansagara D, Englander H, Salanitro A, Kagen D, Theobald C, Freeman M, et al. Risk prediction models for hospital readmission: a systematic review. JAMA. 2011; 306(15): 1688-98. [ Links ]
4. Billings J, Dixon J, Mijanovich T, Wennberg D. Case finding for patients at risk of readmission to hospital: development of algorithm to identify high risk patients. BMJ. 2006; 333: 327-30. [ Links ]
5. Lemke KW, Weiner JP, Clark JM. Development and validation of a model for predicting inpatient hospitalization. Med Care. 2012; 50(2): 131-9. [ Links ]
6. Lewis GH. "Impactibility models": identifying the subgroup of high-risk patients most amenable to hospital-avoidance programs. Milbank Q. 2010; 88(2): 240-55. [ Links ]
7. Nuño-Solinis R, Orueta JF, Mateos M. An Answer to Chronicity in the Basque Country: Primary Care-Based Population Health Management. J Ambulatory Care Manage. 2012; 35(3): 167-73. [ Links ]
8. Orueta JF, Mateos Del Pino M, Barrio Beraza I, Nuño Solinis R, Cuadrado Zubizarreta M, Sola Sarabia C. Estratificación de la población en el País Vasco: resultados en el primer año de implementación. Aten Primaria. 2013; 45(1): 54-60. [ Links ]
9. Johns Hopkins University, School of Public Health: The Johns Hopkins University ACG Case-Mix System. Baltimore (MD): The Johns Hopkins University. Disponible en: http://acg.jhsph.org/index.php?option=com_content&view=article&id =46&Itemid=61. [ Links ]
10. Domínguez-Berjón MF, Borrell C, Cano-Serral G, Esnaola S, Nolasco A, Pasarín MI, et al. Construcción de un índice de privación a partir de datos censales en grandes ciudades españolas (Proyecto MEDEA). Gac Sanit. 2008; 22(3): 179-87. [ Links ]
11. Hanley JA, McNeil BJ. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology. 1982; 143: 29-36. [ Links ]
12. SAS version 9.2. Cary NC: SAS Institute; 2008. [ Links ]
13. Sing T, Sander O, Beerenwinkel N, Lengauer T. ROCR: visualizing classifier performance in R. Bioinformatics. 2005; 21(20): 3940-1. [ Links ]
14. The R Development Core Team. R: A language and environment for statistical computing. Version 2.11.1. Vienna: R Foundation for Statistical Computing ; 2010. [ Links ]
15. Billings J, Blunt I, Steventon A, Georghiou T, Lewis G, Bardsley M.. Development of a predictive model to identify inpatients at risk of re-admission within 30 days of discharge (PARR-30). BMJ Open. 2012; 00: e001667. [ Links ]
16. Orueta JF, Nuño-Solinis R, Mateos M, Vergara I, Grandes G, Esnaola S. Predictive risk modelling in the Spanish population: a cross-sectional study. BMC Health Serv Res. 2013; 13: 269. [ Links ]
17. Orueta JF, Nuño-Solinis R, Mateos M, Vergara I, Grandes G, Esnaola S.. Monitoring the prevalence of chronic conditions: which data should we use? BMC Health Serv Res. 2012; 12: 365. [ Links ]
18. McAna JF, Crawford AG, Novinger BW, Sidorov J, Din FM, Maio V, et al. A predictive model of hospitalization risk among disabled medicaid enrollees. Am J Manag Care. 2013; 19(5): e166-74. [ Links ]
19. Holman CD, Preen DB, Baynham NJ, Finn JC, Semmens JB. A multipurpose comorbidity scoring system performed better than the Charlson index. J Clin Epidemiol. 2005; 58(10): 1006-14. [ Links ]
20. Hippisley-Cox J, Coupland C. Predicting risk of emergency admission to hospital using primary care data: derivation and validation of QAdmissions score. BMJ Open 2013; 3: e003482. [ Links ]
21. Billings J, Georghiou T, Blunt I,Bardsley M. Choosing a model to predict hospital admission: an observational study of new variants of predictive models for case finding. BMJ Open. 2013; 3: e003352. [ Links ]
22. Lewis G. Predictive modeling in action: How virtual wards' help high-risk patients receive hospital care at home. New York: The Commonwealth Fund; 2010. Disponible en: http://www.commonwealthfund.org/~/media/Files/Publications/Issue%20Brief/2010/Aug/1430_Lewis_predictive_modeling_in_action_virtual_wards_intl_brief.pdf. [ Links ]
23. Allaudeen N, Schnipper JL, Orav EJ, Wachter RM, Vidyarthi AR. Inability of providers to predict unplanned readmissions. J Gen Intern Med. 2011; 26(7): 771-6. [ Links ]
24. Quail JM, Lix LM, Osman BA, Teare GF. Comparing comorbidity measures for predicting mortality and hospitalization in three population-based cohorts. BMC Health Serv Res. 2011; 11: 146. [ Links ]
25. Panattoni LE, Vaithianathan R, Ashton T, Lewis GH. Predictive risk modelling in health: options for New Zealand and Australia. Aust Health Rev. 2011; 35(1): 45-51. [ Links ]
26. Wharam JF, Weiner JP. The promise and peril of healthcare forecasting. Am J Manag Care. 2012; 18(3): e82-5. [ Links ]
![]() Dirección para correspondencia:
Dirección para correspondencia:
Juan F Orueta
Centro de Salud de Astrabudua
Calle Mezo, 35
48950 Erandio, Bizkaia
jon.orueta@osakidetza.net

