










 Servicios personalizados
Servicios personalizados
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares en
SciELO
Similares en
SciELO  Similares en Google
Similares en Google 
 Permalink
PermalinkIntroducción
El National Pressure Injury Advisory Panel propuso, en 2016, el cambio del concepto de "úlceras por presión" por "lesiones por presión" (LPP) y redefinió el concepto1. En el conjunto de las heridas crónicas, las LPP destacan por tener alta prevalencia, asociarse a lesiones relacionadas con la dependencia y tener considerable relevancia sociosanitaria por su morbimortalidad, elevado gasto sanitario, deterioro de la calidad de vida y carga de trabajo para sus cuidadores2,3.
Evaluar el conocimiento de los profesionales sanitarios sobre prevención, valoración y tratamiento de las LPP es de suma importancia para contribuir a la implementación de los mejores cuidados basados en la evidencia científica disponible para la prevención y manejo de estas lesiones, y para el incremento de la calidad asistencial. Diversos estudios constatan que el nivel de conocimiento del personal sanitario con respecto a las LPP es bajo4,5, y que los puntos débiles detectados orientan a focalizar las actividades formativas en educación y adiestramiento6-8.
La elaboración de un cuestionario para la evaluación del conocimiento sobre LPP es una tarea ardua, que requiere mucho tiempo y recursos humanos y financieros. Por ello, lo más eficiente es recurrir a cuestionarios consolidados como el Pieper-Zulkowski Pressure Ulcer Knowledge Test® (PZ-PUKT)9, el cuestionario sobre LPP más utilizado a nivel internacional5,10 y más adaptado transculturalmente a otros idiomas: portugués11, chino12 e iraní13.
En1995 se desarrolló el P-PKUT (Pieper Pressure Ulcer Knowledge®)14, con 47 ítems elaborados a partir de la guía Pressure Ulcers in Adult Prediction and Prevention de 1992. Las nuevas recomendaciones científicas hicieron necesario desarrollar el PZ-PUKT9 en 2014, con 72 ítems elaborados por expertos a partir del National Pressure Ulcer Advisory Panel y el European Pressure Ulcer Advisory Panel de 2009-2014.
La versión original del PZ-PUKT9 está en inglés, y es necesaria una adaptación transcultural al español para aplicarlo en nuestro medio asumiendo la validez de contenido conceptual del original15. Los objetivos de este estudio son: a) realizar una adaptación transcultural del PZ-PUKT al español, y b) realizar un estudio observacional transversal con análisis descriptivo, bivariante y psicométrico del PZ-PUKT en español.
Metodología
Adaptación transcultural
Esta fase se realizó entre octubre del 2020 y marzo del 2021, y siguió las 10 etapas recomendadas por la Internacional Society for Pharmacoeconomics and Outcomes Research (ISPOR)16:
Preparación. Revisión bibliográfica. Se obtuvo la autorización de las autoras para hacer la adaptación transcultural al español, y el equipo investigador hizo una revisión minuciosa del cuestionario.
Traducción a la lengua destino. Se realizaron 2 traducciones independientes por 2 profesionales bilingües de lengua madre español, uno del ámbito sanitario y otro que no lo era; ambos licenciados en traducción e interpretación, con 12 y 19 años de experiencia, respectivamente. Valoraron la dificultad de traducción de cada ítem de 1 a 10 y se centraron en el significado conceptual.
Reconciliación. Se compararon las 2 traducciones independientes al español para resolver discrepancias y obtener una única versión por consenso.
Retrotraducción a la lengua original. Se tradujo al inglés de forma independiente la versión de consenso en español por 2 expertos titulados bilingües de lengua madre inglés, uno del ámbito sanitario y el otro no, con 7 y 8 años de experiencia, respectivamente; la dificultad de traducción de cada ítem se valoró de 1 a 10 y se centró en el significado conceptual.
Revisión de la retrotraducción. Se comparó la versión obtenida en la retrotraducción con el cuestionario original para descubrir e investigar las discrepancias entre el original y la versión al español con el fin de asegurar la equivalencia semántica y conceptual de la traducción.
Armonización. Se trató de comparar la versión en español con la adaptación del PZ-PUKT al portugués11 para incrementar el rigor metodológico.
Entrevista cognitiva. Se desarrolló con un grupo multidisciplinar de 7 profesionales con experiencia en atención a personas con LPP de un centro de salud durante 1 h. Después de una introducción, se aplicó la versión del cuestionario obtenida tras la retrotraducción. A continuación, cada participante evaluó la claridad y la relevancia de cada uno de los 72 ítems. Finalmente, se realizó una entrevista grupal semiestructurada exploratoria grabada para indagar sobre el formato, la comprensión y la interpretación del cuestionario, la apariencia de contenido de ítems y el tiempo de cumplimentación.
Revisión de los resultados de la entrevista cognitiva y finalización. El equipo investigador valoró los resultados de la etapa anterior para incorporar las aportaciones pertinentes, con el objetivo de mejorar la traducción final y asegurar la equivalencia cultural.
Corrección del texto. Revisión de la versión final del cuestionario.
Informe final. Descripción de la metodología desarrollada. La validez aparente y de contenido se estudió con método Delphi en 2 rondas por correo electrónico. Para evaluar el instrumento, se envió el cuestionario a un grupo de 4 expertos en LPP, que evaluaron en la primera ronda la apariencia global y el contenido de cada ítem con una escala Likert negativa. Después se analizaron las respuestas proporcionadas y se realizaron las modificaciones pertinentes, enviando nuevamente el cuestionario para conocer la opinión sobre las modificaciones como en primera ronda: apariencia (1, muy mala, a 5, muy buena) y contenido (1, nada relevante, a 5, muy relevante). Con estos datos se determinó la validez aparente y se calculó el índice de validez de contenido (IVC), cociente donde el numerador era el número de expertos con puntuación 4-5 y el denominador el total de expertos, y se consideró adecuado para 4 expertos un IVC ≥0,75.
Estudio observacional
Esta fase se realizó, entre abril y junio de 2021, mediante un estudio transversal multicéntrico con muestreo no probabilístico y cuestionario PZ-PUKT en español autoadministrado, en el Área Sanitaria de A Coruña e Cee.
•Población y ámbito de estudio. El cuestionario se facilitó a 1.148 profesionales que desarrollaban su labor asistencial en 3 de los 5 hospitales del área con servicios de alta incidencia y prevalencia de LPP (críticos, paliativos, hospitalización a domicilio, medulares, medicina interna y traumatología), en 28 de los 52 servicios de atención primaria y en 2 de los 2 centros sociosanitarios. Los responsables de cada servicio invitaron a participar a toda la población potencial: 383 médicos/as, 565 enfermeros/as y 200 técnicos/as en cuidados auxiliares de enfermería (TCAE). El criterio de inclusión fue que estos profesionales hubiesen atendido o atendiesen a pacientes con LPP.
•Recogida de datos. En la recolección de datos, los investigadores facilitaron a los responsables de cada servicio un sobre abierto para cada participante, con el objetivo del estudio, el cuestionario sociodemográfico y el PZ-PUKT en español. En cada servicio se entregó la documentación facilitada en dicho orden, según disponibilidad y horario de trabajo. Los cuestionarios autoadministrados cumplimentados, sin datos personales, se entregaron en sobre cerrado a los responsables, para custodiarlos hasta la recogida por el equipo de investigación, garantizando en todo momento su anonimato.
La captación de la submuestra de 33 profesionales para analizar fiabilidad test-retest se realizó con un muestreo por conveniencia. La segunda cumplimentación del cuestionario se realizó a las 3 semanas de la primera, redistribuyendo cuestionarios codificados alfanuméricamente que vinculaban ambos períodos. Los responsables de cada servicio custodiaron los cuestionarios cumplimentados hasta ser entregados al equipo de investigación.
•Variables. Los conocimientos sobre LPP se evaluaron con los 72 ítems del cuestionario PZ-PUKT en español, no publicados por los derechos de autor acordados, pero a disposición de los interesados a través del autor de correspondencia.
El PZ-PUKT en español consta de 2 partes. La primera incluye 11 ítems para recoger datos sociodemográficos y la segunda 72 ítems para evaluar el conocimiento sobre LPP. La puntuación se basa en la respuesta a los 72 ítems. Hay 42 ítems en los que la opción "verdadero" es la correcta y 30 en los que la opción "falso" es la correcta, siendo las opciones de respuesta "verdadero", "falso" y "no sé". La respuesta correcta suma 1 punto y la incorrecta 0 puntos, considerando a los ítems en blanco o con respuesta "no sé" como incorrectos. La calificación es porcentual, tiene un rango entre 0 y 100, que se obtiene sumando todas las respuestas correctas, que se dividen entre el total de ítems (72) y el resultado se multiplica por 100.
Las variables sociodemográficas fueron: edad (años), género (sexo), actividad (lugar de trabajo), categoría profesional (profesión sanitaria), experiencia (años de trabajo), formación (grado académico), especialidad (formación sanitaria especializada), formación continuada (curso de formación en heridas), lectura (revisión de guías, artículos o libros sobre heridas), internet (búsqueda de información en la web sobre heridas), guías (lectura de guías sobre LPP), tiempo (autocumplimentación de hora de inicio y fin), experto (posgraduado en LPP y/o experto en heridas) y novel (no experto).
•Análisis estadístico. Los datos se analizaron con los softwares IBM SPSS®26 y JAMOVI®2.2.5.
–Análisis descriptivo. El SPSS®26 se utilizó para calcular la frecuencia observada con porcentajes (%) en variables cualitativas y media (x-), rango (R) y desviación típica (DT) en cuantitativas.
–Análisis bivariante. El SPSS®26 se utilizó para comprobar la distribución con la prueba Kolmogórov-Smirnov (K-S) y realizar estadística inferencial con pruebas paramétricas: t de Student (t), análisis de varianza (ANOVA) y coeficiente de correlación de Pearson (r). Nivel de significación: 0,05.
–Análisis psicométrico. Teoría de respuesta al ítem. El JAMOVI®2.2.5 se utilizó para el análisis clásico de ítems, que se complementó con un análisis Rasch para obtener información sobre el rendimiento de ítems y personas de manera independiente, calculando la puntuación latente medida, muy útil para analizar cuestionarios. La estimación de los parámetros empleó el método de estimación conjunta de máxima verosimilitud. La independencia entre ítems se probó con correlaciones residuales de valor <0,3 para el Q3 de Yen. La fiabilidad de las personas se interpreta con los rangos de valores empleados en métodos clásicos. El índice de discriminación se calculó mediante correlación punto-biserial, para mostrar la capacidad de discriminación entre personas con puntuaciones altas y bajas de cada ítem. El índice de dificultad corregido se calculó mediante el cuartil superior e inferior de participantes, para mostrar la proporción de personas que respondieron correctamente cada ítem. La dificultad Rash indicó qué valores suponían mayor (positivos) y menor (negativos) nivel de dificultad, asumiendo que el parámetro de respuesta al azar es 0 y el de discriminación es constante. El ajuste del modelo se estimó con el cuadrático medio ponderado (INFIT) y sensible a valores atípicos (OUTFIT), en el que los índices tienen buen ajuste con valores entre 0,8-1,2 y ajuste aceptable entre 0,5-1,5. Finalmente, se realizó un mapa de Wright para mostrar la dispersión de puntuaciones para los ítems y las personas.
•Fiabilidad. El JAMOVI®2.2.5 se utilizó para estimar la consistencia interna mediante los coeficientes de alfa de Cronbach (α) y omega de McDonalds (ω)
•Estabilidad temporal o fiabilidad test-retest. El SPSS®26 se utilizó para comprobar el coeficiente de correlación intraclase (CCI) y elaborar un diagrama Bland-Altman con nivel de significación de 0,05.
•Validez mediante técnica de grupos conocidos. El SPSS®26 se utilizó para comparar las puntuaciones de conocimiento entre 2 grupos predefinidos (expertos y noveles) con la prueba paramétrica de la t de Student y un nivel de significación de 0,05.
RESULTADOS
Adaptación transcultural
La traducción al español y la retrotraducción al inglés reportaron ítems de difícil traducción (Tabla 1) que los traductores revisaron, resolviendo las discrepancias entre ambas reconciliaciones por consenso.
Tabla 1. Resumen de la adaptación transcultural del PZ-PUKT en español
| Traducción independiente al español | ||
|---|---|---|
| Traductor | Ítems | Palabras (dificultad) |
| Experto bilingüe sanitario | 14 | Hemodynamically unstable (2), malleolus (3), climate (4), hydrocolloid and film dressings (4), non-sting skin prep (4), eschar (5), slough (5), draining (6), drainage (6), granulation tissue (7), shear (7), undermining (7), break down (8) y biofilm (8) |
| Experto bilingüe no sanitario | 10 | Hemodynamically unstable (3), hydrocolloid and film dressings (3), malleolus (3), slough (5), eschar (5), climate (5), undermining (5), granulation tissue (7), shear (7) y biofilm (8) |
| Retrotraducción independiente al inglés | ||
| Traductor | Ítems | Palabras (dificultad) |
| Experto bilingüe sanitario | 13 | Cama de rotación lateral (2), exudativas (2), apósitos de espuma (3), tejido de granulación (3), blanqueamiento (3), apósitos de alginato (3), apósitos hidrocoloides (4), maléolo (4), eritema no blanqueable (5), cizallamiento (6), esfacelo (8), escara (8) y socavación (8) |
| Experto bilingüe no sanitario | 6 | Lecho (4), cizallamiento (4), esfacelo (8), escara (8), maléolo (8) y socavación (8) |
La armonización no se realizó al no conseguir la versión portuguesa adaptada.
La entrevista cognitiva confirmó la idoneidad de formato y la legibilidad del cuestionario, con una cumplimentación (x-: 14 min; R: 19-9; DT: ± 3,4) que se percibió larga. Las preguntas sonda reportaron 5 ítems "poco claros" al valorar apariencia y 8 que "necesitan mejorar" al valorar contenido.
El equipo investigador verificó la calidad de las traducciones y las respuestas a las preguntas sonda, realizó cambios menores para mejorar la equivalencia semanticoconceptual, modificó 3 ítems para mejorar comprensión e interpretación, confirmó con las autoras originales la correcta adaptación de 2 ítems y consolidó la versión final del PZ-PUKT en español. Respecto a la validez de contenido, se incorporaron aclaraciones relacionadas con la práctica clínica habitual que podían producir confusión, obteniendo finalmente muy buena validez aparente y de contenido (IVC, x-: 0,96; R: 1-0,87).
Estudio observacional
•Análisis descriptivo. Las características demográficas, profesionales y academicoformativas de la muestra de 123 sanitarios se presentan en la Tabla 2. El tiempo de cumplimentación fue de x-: 25,6 min; R: 60-9; DT: ± 10,8. La puntuación promedio fue del 73,5% (R: 94-43; DT: ± 10,5) y se distribuyó (-1σ-+1σ) en 4 niveles: 18 (14,63%) obtuvieron "nivel bajo", con ≤ 63% aciertos, 29 (23,58%) "nivel regular", con 64-73%, 62 (50,41) "nivel adecuado", con 74-83% y 14 (11,38) "nivel excelente", con > 84%.
•Análisis bivariante. La distribución normal se confirmó con K-S y las asociaciones entre variables con pruebas paramétricas (Tabla 2), y se observaron diferencias estadísticamente significativas entre la puntuación obtenida y la categoría, la formación académica, la formación sanitaria especializada, la formación en LPP, la búsqueda en Internet sobre LPP, la lectura de guías sobre LPP y el tiempo de cumplimentación.
Tabla 2. Tabla de frecuencias y pruebas de significación estadística
| ANOVA | Frecuencias | Puntuaciones | |
|---|---|---|---|
| n (%) | x- ± DT | p | |
| Actividad | |||
| Hospital | 49 (39,8) | (a) 73,3 ± 8,88 | 0,070 |
| Centro sociosanitario | 11 (8,9) | (a) 66,9 ± 13,6 | |
| Atención primaria/domiciliaria | 63 (51,2) | (a) 74,8 ± 10,8 | |
| Categoría | |||
| Puestos de gestión | 9 (5,7) | (a) 79,0 ± 5,66 | 0,000 |
| Médico/a | 13 (8,3) | (b) 63,1 ± 13,0 | |
| Enfermero/a | 93 (59,2) | (a) 75,7 ± 8,61 | |
| TCAE | 8 (5,1) | (b) 59,2 ± 9,59 | |
| Experiencia | |||
| Menos de 1 año | 3 (2,4) | (a) 56,9 ± 14,0 | 0,101 |
| Entre 1 y 5 años | 16 (13,0) | (a) 72,2 ± 12,4 | |
| Entre 5 y 9 años | 17 (13,8) | (a) 76,3 ± 10,0 | |
| Entre 10 y 14 años | 13 (10,6) | (a) 73,9 ± 8,16 | |
| Entre 15 y 19 años | 17 (13,8) | (a) 74,7 ± 8,77 | |
| 20 años o más | 57 (46,3) | (a) 73,5 ± 10,4 | |
| Formación | |||
| Pregrado universitario | 9 (5,7) | (a) 58,7 ± 9,05 | 0,000 |
| Grado universitario | 99 (63,1) | (b) 74,6 ± 9,62 | |
| Posgrado universitario | 15 (9,6) | (b) 75,3 ± 10,8 | |
| Especialidad | |||
| Ninguna | 105 (85,4) | (a) 73,3 ± 9,80 | 0,000 |
| Enfermería de familia | 7 (5,7) | (b) 86,1 ± 6,36 | |
| Medicina de familia | 7 (5,7) | (c) 61,1 ± 12,8 | |
| Enfermería geriátrica | 2 (1,6) | (a-b-c) 77,7 ± 3,92 | |
| Medicina geriátrica | 2 (1,6) | (a-b-c) 77,0 ± 2,94 | |
| Formación | |||
| Hace 1 año o menos | 21 (17,1) | (a) 79,6 ± 6,56 | 0,000 |
| Hace > 1 pero < 2 años | 17 (13,8) | (a) 78,5 ± 7,26 | |
| Hace 2 o 3 años | 32 (26,0) | (a) 74,0 ± 7,71 | |
| Hace 4 años o más | 37 (30,1) | (a-b) 71,8 ± 11,1 | |
| Nunca | 16 (13,0) | (b) 63,1 ± 12,6 | |
| Lectura | |||
| Hace 1 año o menos | 61 (49,6) | (a) 76,3 ± 9,24 | 0,000 |
| Hace > 1 pero < 2 años | 17 (13,8) | (a) 75,4 ± 7,54 | |
| Hace 2 o 3 años | 25 (20,3) | (a) 70,11 ± 10,4 | |
| Hace 4 años o más | 16 (13,0) | (a) 71,7 ± 10,5 | |
| Nunca | 4 (3,3) | (b) 51,0 ± 9,91 | |
| t de Student | Frecuencias | Puntuaciones | |
| n (%) | x- ± DT | p | |
| Género | |||
| Mujer | 105 (85,4) | 73,6 ± 10,8 | 0,735a |
| Hombre | 18 (14,6) | 72,7 ± 8,90 | |
| Especialidad | |||
| No | 105 (85,4) | 73,3 ± 9,80 | 0,763b |
| Sí | 18 (14,6) | 74,4 ± 14,3 | |
| Experto | |||
| No | 120 (97,6) | 73,3 ± 10,5 | 0,121a |
| Sí | 3 (2,4) | 82,8 ± 5,25 | |
| Internet | |||
| No | 16 (87,0) | 67,1 ± 13,2 | 0,009a |
| Sí | 107 (13,0) | 74,4 ± 9,77 | |
| Guías | |||
| No | 27 (22,0) | 63,5 ± 13,2 | 0,000b |
| Sí | 96 (78,0) | 76,3 ± 7,61 | |
| Pearson | Frecuencias | Puntuaciones | |
| n; x- ± DT | Pearson | p | |
| Edad | 123; 44,2 ± 12 | -0,082 | 0,365 |
| Tiempo | 108; 25,6 ± 10,8 | 0,200c | 0,038 |
DT: desviación típica; TCAE: técnicos/as en cuidados auxiliares de enfermería. at de Student. Prueba de Levene: se asumen varianzas iguales.bt de Student. Prueba de Levene: no se asumen varianzas iguales. Correlación significativa en el nivel 0,05 (bilateral).
•Análisis psicométrico. Teoría de respuesta al ítem. Los resultados del análisis clásico y Rasch se representan en la Tabla 3. La independencia local entre ítems se confirma con un valor de Q3 de Yen < 0,3 para todos los ítems. La fiabilidad para las personas fue de 0,814. El índice de discriminación promedio fue de 0,24 y el índice de dificultad corregida promedio de 0,63. Los ítems tienen un amplio rango de dificultad (R: -5,07-2,62) y todos tienen valores entre 0,5 y 1,5 en los INFIT-OUTFIT, excepto 7 ítems con valores inferiores (15, 16 y 44) o superiores (11, 32, 46 y 50). El mapa de Wright se muestra en la Figura 1.
Tabla 3. Principales características de los ítems
| Ítem | Proporciones de respuesta | Índices del cuestionario | Ajuste del modelo | |||||
|---|---|---|---|---|---|---|---|---|
| Correcta | Incorrecta | No sabe | Discriminación | Dificultad biserial | Dificultad Rasch | INFIT | OUTFIT | |
| 1 (V) | 0,959 | 0,033 | 0,008 | Muy fácil | Pobre | -340,169 | 0,986 | 0,976 |
| 2 (F) | 0,870 | 0,081 | 0,049 | Muy fácil | Regular | -207,908 | 1,004 | 0,945 |
| 3 (F) | 0,911 | 0,024 | 0,065 | Muy fácil | Pobre | -252,618 | 0,936 | 0,918 |
| 4 (V) | 0,480 | 0,423 | 0,098 | Muy difícil | Adecuado | 0,10215 | 1,066 | 1,095 |
| 5 (V) | 0,846 | 0,138 | 0,016 | Muy fácil | Pobre | -186,359 | 1,208 | 1,419 |
| 6 (F) | 0,618 | 0,333 | 0,049 | Difícil | Excelente | -0,52286 | 0,980 | 0,987 |
| 7 (F) | 0,724 | 0,154 | 0,122 | Fácil | Adecuado | -105,719 | 0,981 | 0,968 |
| 8 (V) | 0,862 | 0,114 | 0,024 | Muy fácil | Regular | -200,393 | 1,043 | 0,951 |
| 9 (V) | 0,780 | 0,089 | 0,130 | Fácil | Regular | -139,417 | 1,097 | 1,070 |
| 10 (F) | 0,528 | 0,366 | 0,106 | Difícil | Regular | -0,11487 | 1,090 | 1,108 |
| 11 (F) | 0,984 | 0,016 | 0,000 | Muy fácil | Pobre | -436,191 | 1,030 | 1,522 |
| 12 (V) | 0,780 | 0,138 | 0,081 | Fácil | Excelente | -139,417 | 0,868 | 0,792 |
| 13 (F) | 0,886 | 0,106 | 0,008 | Muy fácil | Pobre | -224,160 | 1,064 | 1,073 |
| 14 (F) | 0,602 | 0,301 | 0,098 | Difícil | Pobre | -0,44683 | 1,138 | 1,159 |
| 15 (V) | 0,992 | 0,008 | 0,000 | Muy fácil | Pobre | -506,980 | 0,988 | 0,426 |
| 16 (V) | 0,991 | 0,008 | 0,000 | Muy fácil | Pobre | -506,980 | 0,987 | 0,405 |
| 17 (V) | 0,285 | 0,122 | 0,593 | Muy difícil | Adecuado | 102,706 | 1,052 | 1,056 |
| 18 (V) | 0,943 | 0,008 | 0,049 | Muy fácil | Pobre | -303,612 | 0,953 | 0,781 |
| 19 (V) | 0,764 | 0,033 | 0,203 | Fácil | Regular | -129,267 | 1,007 | 1,016 |
| 20 (F) | 0,398 | 0,512 | 0,089 | Muy difícil | Adecuado | 0,46844 | 1,024 | 1,016 |
| 21 (V) | 0,935 | 0,016 | 0,049 | Muy fácil | Pobre | -288,808 | 0,923 | 0,704 |
| 22 (V) | 0,764 | 0,154 | 0,081 | Fácil | Pobre | -129,267 | 1,157 | 1,264 |
| 23 (V) | 0,740 | 0,024 | 0,236 | Fácil | Excelente | -114,862 | 0,922 | 0,874 |
| 24 (F) | 0,675 | 0,065 | 0,260 | Normal | Excelente | -0,79996 | 0,903 | 0,890 |
| 25 (F) | 0,659 | 0,276 | 0,065 | Normal | Excelente | -0,71872 | 0,893 | 0,879 |
| 26 (F) | 0,423 | 0,537 | 0,041 | Muy difícil | Pobre | 0,35709 | 1,103 | 1,112 |
| 27 (V) | 0,610 | 0,228 | 0,163 | Difícil | Excelente | -0,48471 | 1,031 | 1,027 |
| 28 (V) | 0,951 | 0,049 | 0,000 | Muy fácil | Pobre | -320,481 | 0,990 | 0,923 |
| 29 (V) | 0,626 | 0,114 | 0,026 | Normal | Adecuado | -0,56133 | 1,004 | 1,010 |
| 30 (V) | 0,902 | 0,041 | 0,057 | Muy fácil | Regular | -242,469 | 0,979 | 0,791 |
| 31 (V) | 0,886 | 0,024 | 0,089 | Muy fácil | Regular | -224,160 | 0,936 | 0,832 |
| 32 (F) | 0,984 | 0,016 | 0,000 | Muy fácil | Pobre | -436,191 | 1,032 | 1,898 |
| 33 (F) | 0,252 | 0,667 | 0,081 | Muy difícil | Pobre | 120,691 | 1,189 | 1,482 |
| 34 (V) | 0,886 | 0,057 | 0,057 | Muy fácil | Pobre | -224,160 | 1,072 | 1,132 |
| 35 (F) | 0,732 | 0,106 | 0,163 | Fácil | Regular | -110,249 | 1,078 | 1,068 |
| 36 (V) | 0,520 | 0,301 | 0,179 | Difícil | Adecuado | -0,07862 | 1,029 | 1,035 |
| 37 (F) | 0,691 | 0,244 | 0,065 | Normal | Adecuado | -0,88324 | 1,019 | 1,024 |
| 38 (F) | 0,976 | 0,008 | 0,016 | Muy fácil | Pobre | -394,176 | 0,998 | 1,383 |
| 39 (V) | 0,691 | 0,260 | 0,049 | Normal | Adecuado | -0,88324 | 1,005 | 1,023 |
| 40 (V) | 0,569 | 0,163 | 0,268 | Difícil | Excelente | -0,29764 | 0,975 | 0,959 |
| 41 (V) | 0,504 | 0,358 | 0,138 | Difícil | Excelente | -0,00626 | 0,953 | 0,950 |
| 42 (V) | 0,431 | 0,341 | 0,228 | Muy difícil | Excelente | 0,32033 | 0,949 | 0,928 |
| 43 (F) | 0,699 | 0,228 | 0,073 | Fácil | Adecuado | -0,92574 | 0,975 | 0,979 |
| 44 (V) | 1,000 | 0,000 | 0,000 | Muy fácil | Pobre | -506,980 | 2,28e-16 | 5,58e-23 |
| 45 (V) | 0,959 | 0,024 | 0,016 | Muy fácil | Pobre | -340,169 | 0,927 | 0,617 |
| 46 (V) | 0,992 | 0,008 | 0,000 | Muy fácil | Pobre | -506,980 | 1,019 | 1,788 |
| 47 (V) | 0,854 | 0,041 | 0,106 | Muy fácil | Pobre | -193,223 | 1,010 | 1,034 |
| 48 (V) | 0,341 | 0,407 | 0,252 | Muy difícil | Adecuado | 0,73742 | 1,017 | 1,000 |
| 49 (V) | 0,992 | 0,008 | 0,000 | Muy fácil | Pobre | -506,980 | 1,001 | 0,643 |
| 50 (F) | 0,081 | 0,854 | 0,065 | Muy difícil | Pobre | 262,120 | 1,037 | 1,614 |
| 51 (V) | 0,927 | 0,041 | 0,033 | Muy fácil | Pobre | -275,580 | 0,977 | 0,854 |
| 52 (V) | 0,276 | 0,593 | 0,130 | Muy difícil | Excelente | 107,084 | 0,937 | 0,895 |
| 53 (F) | 0,740 | 0,163 | 0,098 | Fácil | Regular | -114,862 | 1,060 | 1,061 |
| 54 (F) | 0,732 | 0,073 | 0,195 | Fácil | Adecuado | -110,249 | 1,023 | 1,020 |
| 55 (F) | 0,984 | 0,016 | 0,000 | Muy fácil | Pobre | -436,191 | 1,008 | 0,728 |
| 56 (F) | 0,764 | 0,098 | 0,138 | Fácil | Excelente | -129,267 | 0,893 | 0,823 |
| 57 (F) | 0,911 | 0,073 | 0,016 | Muy fácil | Pobre | -252,618 | 1,054 | 1,056 |
| 58 (V) | 0,805 | 0,089 | 0,106 | Fácil | Excelente | -155,657 | 0,917 | 0,817 |
| 59 (V) | 0,959 | 0,024 | 0,016 | Muy fácil | Pobre | -340,169 | 0,975 | 0,756 |
| 60 (V) | 0,967 | 0,033 | 0,000 | Muy fácil | Pobre | -363,943 | 0,956 | 0,568 |
| 61 (V) | 0,951 | 0,033 | 0,016 | Muy fácil | Pobre | -320,481 | 0,964 | 0,724 |
| 62 (F) | 0,390 | 0,341 | 0,268 | Muy difícil | Excelente | 0,50598 | 0,956 | 0,923 |
| 63 (V) | 0,398 | 0,390 | 0,211 | Muy difícil | Excelente | 0,46844 | 0,944 | 0,924 |
| 64 (F) | 0,797 | 0,081 | 0,122 | Fácil | Regular | -150,094 | 0,996 | 1,063 |
| 65 (V) | 0,976 | 0,016 | 0,008 | Muy fácil | Pobre | -394,176 | 0,997 | 1,259 |
| 66 (V) | 0,780 | 0,130 | 0,089 | Fácil | Regular | -139,417 | 0,981 | 1,026 |
| 67 (V) | 0,764 | 0,057 | 0,179 | Fácil | Adecuado | -129,267 | 0,922 | 0,929 |
| 68 (F) | 0,659 | 0,138 | 0,203 | Normal | Adecuado | -0,71872 | 1,017 | 1,024 |
| 69 (F) | 0,699 | 0,073 | 0,228 | Fácil | Excelente | -0,92574 | 0,857 | 0,832 |
| 70 (V) | 0,927 | 0,033 | 0,041 | Muy fácil | Pobre | -275,580 | 0,970 | 0,805 |
| 71 (F) | 0,911 | 0,024 | 0,065 | Muy fácil | Regular | -252,618 | 0,879 | 0,722 |
| 72 (F) | 0,106 | 0,732 | 0,163 | Muy difícil | Regular | 232,025 | 0,951 | 0,988 |
V: la respuesta correcta es verdadero; F: la respuesta correcta es falso. Discriminación: excelente (> 0,39), adecuado (0,30-0,39), regular (0,20-0,29) y pobre (0,01-0,19). Dificultad: muy fácil (> 0,75), fácil (0,55-0,74), normal (0,45-0,54), difícil (0,25-0,44) y muy difícil (< 0,25). Dificultad Rasch: valores negativos significan menor dificultad y valores más altos mayor dificultad. INFIT/OUTFIT: estadístico cuadrático medio ponderado/cuadrático medio sensible a valores.

En la izquierda se representa la densidad de personas, indicando la distribución de las puntuaciones obtenidas por personas en unidades logit. Un valor superior a 0 indica buen conocimiento e inferior, mal conocimiento. En la derecha se distribuyen los ítems de acuerdo con su nivel de dificultad.
Figura 1. Mapa de Wright del modelo del PZ-PUKT en español.
•Fiabilidad. El α fue de 0,833 y el ω fue de 0,832.
•Estabilidad temporal o fiabilidad test-retest. El CCI fue de 0,956. En la figura 2 se muestra la estabilidad con el diagrama de Bland-Altman.
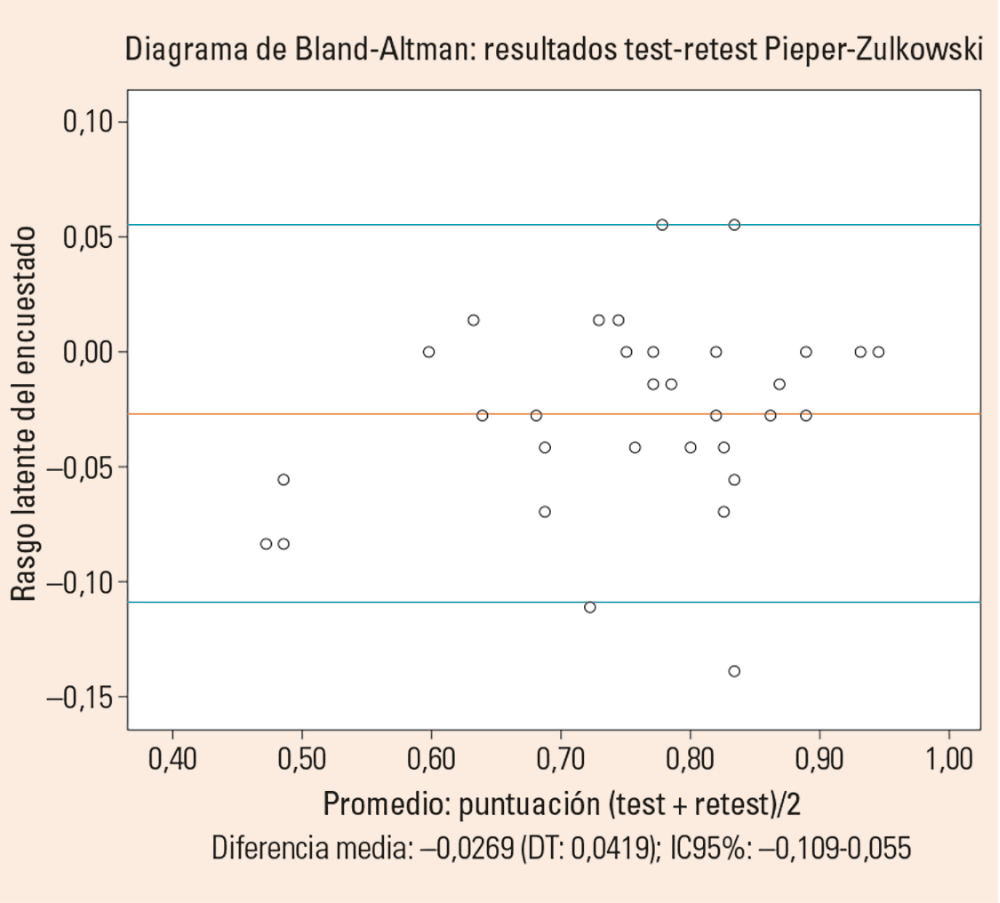
Eje Y: corresponde a las diferencias entre la puntuación del test y del retest (A-B); eje X: representa el valor de la media de ambos (A + B/2) como estimador del valor real; líneas verdes: intervalo de confianza con la diferencia media de ± 1,96 DT; línea roja: valor medio determinado por A - valor medio determinado por B.
Figura 2. Diagrama de Bland-Altman obtenido con las puntuaciones totales del test-retest utilizando el PZ-PUKT en español.
•Validez mediante técnica de grupos conocidos. El grupo de 8 (6,5%) expertos, 5 posgraduados en LPP y 3 expertos en heridas, obtuvo una puntuación significativamente mejor (p = 0,009) que los 115 (93,5%).
Discusión
Adaptación transcultural
Realizado el proceso sistemático y estandarizado de la ISPOR16, la mayoría de los ítems consiguieron "alta equivalencia" respecto a la versión original. Los que no lo hicieron obtuvieron "moderada equivalencia", al incluir expresiones que se emplean de forma diferente para un mismo concepto, pero que condujeron a una retrotraducción que no modificó sustancialmente el significado original. Además de buena equivalencia semanticoconceptual, el cuestionario tiene muy buena validez aparente y de contenido.
Estudio observacional
La puntuación promedio es inferior a la obtenida en dos estudios con PZ-PUKT9,14 y superior al resto de estudios realizados con el instrumento8,11-13,17,18. Las autoras no establecen puntuaciones de corte para que cada investigador o clínico las ajuste al objetivo de su proyecto14,17,19,20, estableciendo este estudio 4 niveles sobre la base de la distribución y dificultad observada.
Los participantes con formación reciente, los que buscaron información en Internet y/o leyeron guías sobre LPP obtuvieron mejores puntuaciones, con resultados similares a los de otros estudios12,20. El tiempo de cumplimentación es similar a otros estudios8,9,11,18, y conforme aumenta lo hace la puntuación, quizá porque los profesionales con más conocimientos se detienen más para reflexionar. Pero la baja tasa de respuesta (11%) y la poca participación de medicina y TCAE impide sacar conclusiones categóricas, quizás el alto número de ítems y el tiempo de cumplimentación disminuyan la participación.
El análisis Rasch mostró características psicométricas aceptables para validar el constructo, asumiendo la unidimensionalidad e independencia local de ítems.
Pero no apoya completamente el ajuste en la muestra estudiada, mostrando muchos ítems tan poca dificultad que apenas discrimina y 7 ítems que superan los valores de ajuste establecidos: 5 abordan aspectos sobre prevención, uno sobre categorización y otro sobre descripción de heridas. De este modo, el nivel de dificultad es bajo para estos profesionales y habría que confirmar si en otras muestras sucede lo mismo, o este amplio rango de dificultad facilita identificar profesionales con bajo y alto nivel de conocimiento, como indican Moharramzadeh et al.13. Como en otros estudios, los ítems con menor dificultad (15, 16, 44 y 46) abordan aspectos sobre la prevención8,9,11,18 y los de mayor dificultad (50, 72, 33, 17 y 52) abordan las 3 temáticas del cuestionario18,21: prevención, categorización y descripción de la herida.
La fiabilidad obtenida indica buena consistencia interna, sin ítems cuya eliminación incremente sustancialmente estos valores. Una fiabilidad parecida a la de estudios de tamaño similar8,9,11,18,22 e inferior a la obtenida con muestras superiores12,13,18, que induce a pensar que la consistencia se incrementará en estudios con mayor tamaño.
La concordancia de las valoraciones obtenidas al determinar la fiabilidad test-retest con el CCI es excelente, mejorando los valores observados13, con una estabilidad aceptable, con algún punto fuera del intervalo de confianza, que no se analizó en estudios previos8,9,11,18,22.
Por último, la puntuación de profesionales expertos fue mayor que la de noveles, confirmando la validez diferencial del PZ-PUKT en español mediante técnica de grupos conocidos.
Limitaciones
La realización de la entrevista cognitiva en un único centro de salud puede haber limitado la identificación de problemas. Es posible un sesgo de autoselección, por la participación de profesionales motivados que produce una distorsión en los resultados hacia un mayor conocimiento. El muestreo no probabilístico hace que ni la precisión descriptiva ni las conclusiones categóricas sean representativas. La prueba de validez mediante técnica de grupos conocidos se realizó con 2 grupos de tamaño desequilibrado, lo que puede introducir un sesgo importante. No se realizó un análisis factorial para confirmar la posibilidad de dividir el instrumento en 3 subescalas (prevención, categorización y descripción de la herida) por el tamaño muestral necesario.
Conclusiones
El PZ-PUKT en español tiene buena validez aparente y de contenido con respecto a la versión original, y muestra unas características psicométricas apropiadas. Aunque precisa de estudios que evalúen sus propiedades en otras muestras y la posibilidad de dividir el instrumento en 3 subescalas, podemos confirmar que es un instrumento válido y fiable para medir el conocimiento sobre LPP.

