








Meu SciELO
 Serviços customizados
Serviços customizadosServiços Personalizados
Journal
Artigo
 texto em
texto em  Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em
SciELO
Similares em
SciELO -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkAnales de Psicología
versão On-line ISSN 1695-2294versão impressa ISSN 0212-9728
Anal. Psicol. vol.37 no.2 Murcia Mai./Set. 2021 Epub 21-Jun-2021
https://dx.doi.org/10.6018/analesps.37.2.344391
Psicología Cognitiva
¿El Retén Episódico de Baddeley es independiente del ejecutivo central? Una nueva medida del Retén Episódico
2 Department of Developmental and Educational Psychology. Universidad Nacional de Educación a Distancia (UNED).
El Retén Episódico (RE) está tomando un creciente papel central en las explicaciones sobre el funcionamiento de la memoria operativa. De hecho, los últimos estudios de Baddeley y sus colaboradores sitúan al RE en el corazón del sistema de memoria. Recientemente la discusión también atañe a si este componente de la memoria operativa presenta una naturaleza independiente respecto a los recursos del ejecutivo central. Algunos estudios muestran como en tareas automatizadas, la construcción y mantenimiento de elementos almacenados en el RE no requieren de recursos desde el ejecutivo central.
El presente trabajo pretende analizar esta cuestión para lo que se toman diferentes variables y se ha diseñado una nueva prueba para medir el RE. En esta prueba de doble tarea, la tarea de procesamiento consiste en la lectura de textos sencillos con unos espacios en blanco que deben completarse con las palabras clave. Los resultados muestran cómo a pesar del aumento del procesamiento debido al incremento de la longitud de los textos, no se produce un aumento en la carga del ejecutivo central, ni en la creación de los agrupamientos de información, ni en su mantenimiento. Por ello, pensamos que el RE bajo ciertas circunstancias opera de forma independiente al ejecutivo central.
Palabras clave: Memoria Operativa; Retén Episódico; Ejecutivo Central; Lectura; Memoria a Largo Plazo
Introducción
La Memoria Operativa (MO) se ha convertido en un componente esencial para explicar el funcionamiento cognitivo. Se entiende básicamente como un sistema de memoria activo donde se procesa y mantiene temporalmente la información requerida durante la realización de las tareas cognitivas. A pesar de la relevancia que se le otorga desde los principales modelos cognitivos, no existe aún un acuerdo general sobre su naturaleza y conceptualización (véase Miyake y Shah, 1999). Sin embargo, los modelos explicativos de la MO más relevantes coinciden en destacar principalmente dos rasgos característicos: 1) la participación de un Ejecutivo Central de dominio general encargado principalmente de la focalización y cambio atencional, la activación y actualización representacional, y la inhibición de procesos automáticos e información irrelevante (véase Baddeley, 2007; Cowan, 2005; Engle, 2002; Miyake, Friedman, Emerson, Witzki y Howerter, 2000); y 2) el sistema dispone de unos recursos limitados para acometer su doble función básica: el almacenamiento temporal de la información relevante para la tarea en curso y, de forma simultánea, el procesamiento de esa información u otra concurrente en la tarea (Baddeley y Logie, 1999; Just y Carpenter, 1992).
Los trabajos de los últimos años han reactivado el debate sobre el modo en el que se relaciona la MO con el contenido almacenado en la Memoria a Largo Plazo (MLP). No está claro cómo la MO emplea los conocimientos previos relacionados con la tarea en curso para mejorar su funcionamiento, y tampoco está claro si lo hace optimizando la función de procesamiento, de almacenamiento o de ambas. Sin embargo, los expertos coinciden en señalar que la memoria operativa se nutre de la información contenida en la MLP, resultando determinantes los conocimientos semánticos, sintácticos y gramaticales almacenados (Baddeley, 2010). A este respecto, por ejemplo, se sabe que el recuerdo de palabras conocidas es sustancialmente mejor que el de palabras desconocidas, lo que pone de manifiesto la influencia del conocimiento almacenado en la MLP. Del mismo modo, es más sencillo recordar las palabras que componen una frase frente a un listado de palabras no relacionadas (como ya encontró Brener en sus trabajos de 1940).
En este mismo sentido, diferentes estudios muestran cómo la ejecución experta se fundamenta en el uso de claves de recuperación más eficientes que permiten reducir el tiempo de procesamiento y favorecen el manejo de mayor cantidad de información. La mejora del procesamiento resultaría en una menor demanda de recursos, lo que permitiría una mayor capacidad “residual” de recursos disponibles para el almacenamiento (Daneman y Carpenter, 1980; Ericsson y Kintsch, 1995; Kane, Hambrick, Tuholski, Wilhelm, Payne y Engle, 2004). Asimismo, el uso del conocimiento previo también se traduce en una mejora de la capacidad de almacenamiento del sistema, lo que puede estar relacionado con el uso de estrategias orientadas directamente al almacenamiento. En este sentido, ya desde mediados del siglo XX es conocido que el uso de estrategias de “agrupamiento” (“chunking”) de la información permite “extender” la capacidad de almacenamiento a corto plazo (veasé, por ejemplo, Miller, 1956; Tulving y Patkau, 1962; Ericsson y Kintsch, 1995).
En definitiva, aunque la implicación e incidencia de los conocimientos previos es incuestionable, queda por esclarecer de qué modo se relaciona e integra la información contenida en la MLP con la información activa que se gestiona, se manipula y mantiene en la MO. En la actualidad, este aspecto está siendo objeto de particular atención en referencia a los procesos de integración o “enlace” (“binding”) que necesariamente median la construcción de los “chunks” y que parecen mostrarse como parte principal de las operaciones de la MO.
Modelo Multicomponente de Baddeley y Hitch
Entre las propuestas teóricas más relevantes sobre la MO destaca por su particular influencia el modelo multi-componente propuesto por Baddeley y Hitch (1974; Baddeley, 1986, 2000) que tomaremos como referencia en el presente trabajo. Esta teoría presenta un sistema de MO que incluye cuatro componentes principales: dos subsistemas esclavos de almacenamiento temporal —el lazo fonológico y la agenda viso-espacial—, un sistema de control atencional —el ejecutivo central—, y un almacén temporal incorporado posteriormente -el retén episódico- encargado de coordinar la información activa presente en la MO con la memoria a largo plazo (véase Figura 1).
El lazo fonológico y la agenda viso-espacial son subsistemas especializados en el procesamiento y mantenimiento transitorio de la información verbal y viso-espacial respectivamente. Ambos subsistemas están formados por un almacén pasivo y un componente de procesamiento para refrescar (reactivar) la información.
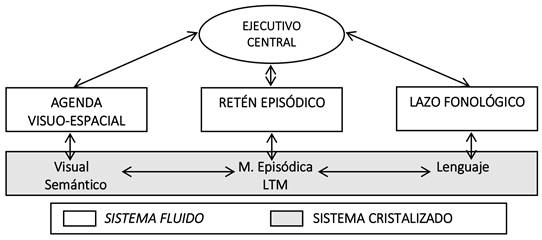
Por su parte, el ejecutivo central (EC) coordina y gestiona el resto de componentes de la MO controlando los recursos atencionales y monitorizando el procesamiento de la información, siendo así el responsable de la dirección y regulación de la actividad dentro del sistema cognitivo. Inicialmente, fue concebido con capacidad para el procesamiento y el almacenamiento; sin embargo, posteriormente se han ido asociando estas funciones a diferentes componentes. De este modo, el EC sería el encargado del procesamiento y control de los recursos, mientras que el almacenamiento ha pasado a considerarse como un proceso adicional dependiente de otro componente del sistema: el retén episódico (RE, en adelante).
El RE añadido por Baddeley en el año 2000 se presenta como un componente de almacenamiento temporal de carácter multimodal, accesible a la conciencia y de capacidad limitada (Baddeley, Hitch y Allen, 2009; Allen, Baddeley y Hitch, 2014). Es el “espacio mental” en el que se integra la información proveniente de los subsistemas esclavos (lazo fonológico y viso-espacial) con la información semántica y lingüística relevante a la tarea almacenada en la MLP, lo que permitiría combinar toda la información e integrarla formando agrupaciones (chunks) multidimensionales en lo que Baddeley denomina “episodios”. Para ello, requiere de un espacio de almacenamiento episódico que, según los últimos trabajos (Baddeley et al., 2009; Baddeley, Allen y Hitch, 2011), parece presentar un carácter más pasivo de lo que se propuso inicialmente (Baddeley, 2000).
En concreto, se propone que el procesamiento requerido para la integración de información (“bindings”) bajo determinadas condiciones (escaso nivel de complejidad, materiales habituales y/o relacionados…) está básicamente automatizado y no demanda soporte adicional por parte del EC, de modo que el mantenimiento de las agrupaciones (“chunks”) depositadas en el RE no se ve afectado por las demandas del procesamiento (Baddeley et al., 2009). De esta manera, se apunta que en tales condiciones no debe producirse interferencia entre la carga cognitiva necesaria para la realización del procesamiento de la información, y la demandada para el almacenamiento y mantenimiento de la misma en el RE. En este trabajo se presentan cuatro experimentos en los que, a partir de diferentes condiciones y tareas concurrentes, van comparando la ejecución de los sujetos en la memorización de tres tipos de conjuntos de palabras. A partir de un mismo “set” de palabras, se construyen: 1) listados de esas palabras escogidas al azar y que no presentan una estructura sintáctica “constrained lists”, 2) frases con cierto sentido sintáctico con esas mismas palabras “constrained sentences” (véase Tabla 1). Además, en algún experimento 3) también se utilizan frases extraídas de noticias, que por tanto tienen una estructura sintáctica correcta y no emplean las mismas palabras que los otros dos conjuntos “open sentences”. El objetivo del uso del mismo pool de palabras es que la interferencia pro-activa minimizara la contribución de la memoria episódica y semántica a largo plazo, obligando así a los participantes a confiar en la agrupación temporal existente en la memoria de trabajo para sustentar su recuerdo, es decir, deben basarse en la estructura sintáctica de las frases que se van construyendo con esas palabras. En un caso la estructura existe en otros casos es casi inexistente. De este modo se limitan o igualan los componentes semánticos para evitar su efecto facilitador en la integración de información (binding). Como tarea secundaria simultánea, se utilizan en los diferentes experimentos diferentes tareas, como conteo hacia atrás, tareas de N-back con distintas condiciones, test de supresión articulatoria y tareas viso-espaciales.
En términos generales el trabajo muestra como a pesar del uso de diferentes tareas secundarias para cargar el EC, los resultados son bastante estables mostrando que la mejor ejecución se produce cuando las palabras se presentan en una estructura sintáctica más reconocible, sin encontrar diferencias entre una presentación oral o visual de los ítems. Asimismo, la mayor proporción de errores de tipo semántico se producen en mayor medida cuando la estructura sintáctica es adecuada indicando que la lectura se realiza de forma más superficial guiados por la sintaxis. La otra cuestión relevante es que la ejecución en la tarea secundaria, no se ve afectada, por lo que se confirma la falta de implicación del EC en la tarea primaria.

Esta nueva articulación del modelo (Baddeley et al., 2011) sitúa al retén episódico en el corazón de la MO (véase Figura 2), implicando al EC en las funciones de integración y mantenimiento de la información dentro del propio RE sólo cuando los procesos que sustentan esa integración (procesos de “binding”) no han sido automatizados; mientras que cuando se realizan de forma automatizada ya no se requiere de la participación del EC -ni en la integración, ni en el mantenimiento- (véase también Allen y Baddeley, 2009; Baddeley et al., 2009, y Allen, Baddeley y Hitch, 2006).

Figura 2. Modelo revisado de Memoria Operativa en el Sistema fluido (Baddeley, Allen y Hitch, 2011). Aunque la nueva propuesta sólo incluye los sistemas de carácter fluido, los autores no han modificado el modo en el que estos sistemas fluidos se relacionan con el sistema cristalizado en la Memoria a Largo Plazo.
Es en este marco donde se sitúa nuestro principal interés: analizar si, como afirma Baddeley, el retén episódico es parcialmente independiente del ejecutivo central y, por tanto, en determinadas condiciones puede operar sin requerir una asistencia específica del EC. Esto nos introduce en el debate sobre la independencia o no entre las dos funciones básicas de la MO (procesamiento y almacenamiento), donde esta propuesta de Baddeley contrasta en cierta medida con otros modelos teóricos que siguen manteniendo que ambas funciones -procesamiento y almacenamiento- están interrelacionadas. Estas concepciones suponen que, en la realización de cualquier tipo de tarea, el EC maneja un único pool de recursos, por lo que la gestión de los recursos disponibles implica una transferencia (trade-off) entre ambas funciones (Barrouillet, Bernardin, Portrat, Vergauwe y Camos, 2007; véase asimismo p. ej., Daneman y Carpenter, 1980; Case, 1985; Turner y Engle, 1989; Just y Carpenter, 1992; Anderson, Reder y Lebière, 1996).
En concreto, nuestro trabajo pretende continuar en la línea de los estudios presentados por Baddeley y cols. (2009) planteados previamente (véase Tabla 1) en donde toman como medida del RE la capacidad de almacenamiento de los sujetos en tareas de recuerdo sobre distintos tipos de listados de palabras en donde tratan de limitar sus propiedades semánticas a fin de evitar el efecto de facilitación de la integración semántica de la información; es decir, evitar el “binding” o integración semántica. Estos estudios han mostrado que el aumento en la carga de procesamiento en estas oraciones “constreñidas/comprimidas” puede ocurrir presumiblemente sin ninguna interferencia en el almacenamiento, al encontrar que el mantenimiento de palabras es significativamente mayor en comparación con su incidencia en la lista restringida.
De forma particular, nuestro trabajo tiene como objetivo contrastar, pero de un modo diferente, los resultados presentados por Baddeley et al. (2009) donde toman como medida del RE la capacidad de almacenamiento de los sujetos en tareas de recuperación en diferentes tipos de listas de palabras mientras realizan una tarea concurrente que requiere recursos del EC. Como describimos anteriormente, la idea es tratar de mostrar cómo se puede aumentar la carga de procesamiento en la tarea secundaria (concurrente) sin interferir significativamente con el almacenamiento y el mantenimiento de la información en la tarea primaria.
Por ello, en el presente trabajo exploramos una nueva tarea de recuerdo en la que los participantes deben leer comprensivamente unos textos narrativos sencillos cuyas frases están diseñadas para que la comprensión no demande apenas recursos atencionales y, por tanto, exista una mínima participación del EC, así como una mínima interferencia en el mantenimiento de los “chunks” en el RE. De este modo, nuestra propuesta pretende el mismo objetivo que los estudios de Baddeley et al. (2009), pero en dirección opuesta: en lugar de evitar o limitar los aspectos semánticos y apoyarse en los aspectos sintácticos, se propone una tarea que utiliza contextos semánticos muy simples para generar el mismo efecto minimizador en la participación del EC. Así, se pretende registrar la amplitud pasiva del RE con el mínimo concurso del EC, mediante el uso de frases de fácil comprensión, que se coordinan en un contexto de la comprensión global. Pensamos, además, que de este modo en las pruebas habituales de doble tarea para registrar la memoria operativa —como las que se emplean en nuestro estudio—, los recursos del EC pueden dedicarse en mayor medida a la “re-activación” de palabras previamente empleadas o conocidas gracias a la representación semántica situacional generada durante la comprensión, como suele suceder en las tareas cotidianas. Como se detalla a continuación, esto supone un registro más “ecológico” del funcionamiento de la MO en general, y del propio RE en particular, ya que se miden de un modo más natural todos los recursos disponibles del sujeto.
La medida del Retén Episódico
Nuestra propuesta pretende analizar el funcionamiento del RE y su dependencia o no de los procesos atencionales generales y para ello se debe registrar específicamente el Retén Episódico, es decir, la capacidad que tiene de almacenar los “chunks” que se construyen y mantienen.
Pero, además, pensamos que ese registro debe hacerse en un contexto cognitivamente más natural que el que implica el tradicional paradigma de la doble-tarea o del “procesamiento concurrente” orientado a comprometer los recursos del EC. Para ello se emplea una tarea habitual de procesamiento cognitivo que requiere manejar la información activada en la MO así como aquella contenida en la MLP que esté relacionada a fin de integrarla y crear agrupamientos que deben ser mantenidos en el tiempo; es decir, una tarea que implica necesariamente el uso “natural” del RE. Asimismo, no podemos olvidar la estrecha y conocida relación entre las medidas de MO y la comprensión lectora (véase p.ej., Daneman y Merikle, 1996; Hannon y Daneman, 2001, 2004; Cain, Oakhill y Bryant, 2004; Vukovic y Siegel, 2006; Carretti, Borella, Cornoldi y De Beni, 2009; García-Madruga et al., 2013; García-Madruga, Gómez-Veiga y Vila, 2016).
En el trabajo que presentamos se usa una prueba verbal en la que los participantes deben realizar la lectura de diversos textos atendiendo a que según el propio Baddeley (2000, 2007, 2012) el RE debe ser el espacio mental en el que deben llevarse a cabo los procesos implicados en la comprensión lectora.
Asimismo, para asegurarnos de la participación del RE, el recuerdo que deben realizar los sujetos en esta nueva tarea, se produce transcurridos al menos 20 segundos después de la última palabra clave activada, ya que todos los textos contienen una parte introductoria de lectura para forzar el tiempo de demora, a fin de incorporar recursos más a largo plazo además de los propios que ofrece el lazo fonológico o la MCP si no se permite el refresco de la información (véase Alloway y Ledwon, 2014; Conway y Engle, 1994; Cowan, Wood, Nugent y Treisman, 1997; Cowan 2001). Tras estas frases introductorias, los textos presentan una serie de frases incompletas que deber ser completadas con las palabras clave previamente activadas.
La nueva prueba se ha diseñado a partir de la Prueba de Amplitud de Razonamiento basada en Analogías (véase Gutiérrez-Martínez, García-Madruga, Carriedo, Vila y Luzón, 2005; García-Madruga, Gutiérrez-Martínez, Carriedo, Luzón y Vila, 2007) en la que los participantes deben leer en voz alta una serie de sencillas analogías verbales, encontrar y decir en voz alta la solución, y recordar al final las palabras-solución de cada una de ellas. En la nueva prueba el procedimiento completo se compone de dos fases, lo que permite que se produzcan dos registros de la MO: un primer índice de medida en base a la prueba de analogías señalada, que registra básicamente el EC, y una segunda medida específica de la nueva tarea, orientada al registro de los procesos que suceden en el Retén Episódico. El nuevo procedimiento exige a los participantes la realización de una segunda tarea que consiste en leer comprensivamente pequeños textos en los que faltan algunas palabras. A fin de conseguir la comprensión correcta de los relatos, los sujetos deben completar los huecos de los textos con las palabras inferidas y almacenadas previamente durante la tarea de analogías.
Así pues, el nuevo procedimiento se compone de dos fases consecutivas: una primera con la prueba de analogías que denominaremos “ANALOGY”, y una segunda fase con la nueva tarea de textos denominada “CONTEX”.
1) (ANALOGY) los sujetos comienzan la prueba resolviendo series crecientes de analogías (2, 3, 4 y 5) cuyo resultado debe ser almacenado y recordado al finalizar cada serie en su orden correcto de aparición (se deben recuperar todas las palabras almacenadas de cada serie; 2, 3, 4 o 5)
2) (CONTEX) a continuación se presenta un texto con una breve introducción y una serie de frases (correspondientes con el número de analogías que contiene la serie) que finalizan con un espacio en blanco que debe ser completado recordando las palabras almacenadas en la fase 1 (el resultado de las analogías). De este modo, se registra el recuerdo de las palabras clave en dos momentos: uno inmediato tras resolverse las analogías y un segundo recuerdo demorado que está integrado en los textos (véase Figura 3).

Como hemos adelantado, la primera premisa que debe cumplir el nuevo índice de medida es que registre los procesos específicos del RE con una mínima o nula participación del EC, para lo que, como ya hemos avanzado, se ha seguido un planteamiento inverso al realizado por Baddeley y cols. (2009) en el desarrollo de la tarea. En lugar de evitar los procesos semánticos, empleamos una tarea que requiere necesariamente de este tipo de procesos para conseguir la comprensión. El factor clave es que los textos empleados en la nueva medida son sencillos y los datos de los estudios piloto previos no encontraron diferencias significativas ni en velocidad lectora ni en el nivel de comprensión entre adolescentes. Por tanto, los normolectores pueden realizar de forma semi-automática la integración semántica -inter e intra sentencias- construyendo el modelo representacional del texto de forma simple. Así, nuestra tarea hace aún más automáticos los enlaces-procesos necesarios para ejecutar la tarea, ya que, al emplearse frases sintácticamente sencillas y similares, con contenidos poco demandantes entendemos que la prueba está diseñada para hacer aún más automáticos los enlaces-procesos necesarios. Es importante destacar, que se contrastó previamente que el contenido semántico de las frases no permitía adivinar las palabras clave sin la pre-activación previa ya que los textos se diseñaron de tal modo que los huecos en blanco pudieran ser completados por diferentes palabras, siendo la palabra clave “adivinada” en porcentajes inferiores al 5%.
En suma, consideramos que al resultar una tarea poco demandante para lectores expertos (universitarios), pensamos que su realización requiere una activación mínima de los recursos ejecutivo-atencionales del EC, lo que permite atribuir las diferencias encontradas en la nueva tarea a las capacidades independientes o específicas del RE. De este modo, podría contrastarse la nueva propuesta de Baddeley en la que afirma la relativa independencia del RE y su carácter eminentemente pasivo.
CONTEX, una propuesta de registro ecológico de la amplitud del Retén Episódico
Nuestra idea, además, también giraba en torno a la posibilidad de realizar un registro del retén episódico más ecológico o natural, es decir contextualizado. Entendemos que en la nueva tarea esta contextualización sucede a través de dos vías diferentes. En primer lugar, la recuperación de palabras previamente almacenadas-activadas sucede en el contexto facilitador proporcionado por la realización previa de la tarea de analogías. Asimismo, el modelo representacional que se debe construir para conseguir la comprensión de los nuevos textos de la segunda parte de tarea implica la “activación” y uso de conocimientos previos que suponen un nuevo contexto semántico favorecedor para “re-activar” las palabras clave “pre-activadas”.
Hemos tratado de lograr una contextualización de la tarea en la que los recursos de la MO se empleen de forma natural, tal y como se usan en las tareas cotidianas donde se mantiene la unión funcional del procesamiento y almacenamiento. De este modo, pretendemos alejarnos de los procedimientos en los que las tareas concurrentes empleadas no están relacionadas de forma natural y por tanto sirven a objetivos diferentes. Por ejemplo, en la clásica Prueba de Amplitud Lectora (RST de Danneman y Carpenter, 1980) el sujeto debe leer una serie de frases e ir almacenando la última palabra de cada frase para recuperarlas en su orden correcto cuando finaliza cada serie. Ambas tareas son independientes, de hecho, el investigador podría elegir otra palabra para recordar en lugar de la última y el resultado seguiría siendo el mismo ya que las tareas no están conectadas. Incluso, la tarea puede ser resuelta de forma correcta sin realizar una comprensión total de las frases, sólo una lectura superficial de las mismas. Sin embargo, la lectura comprensiva que realizan los lectores en sus contextos naturales implica ir almacenando aquellos elementos relevantes que favorecen la comprensión, y no aquellos “ítems” situados en un determinado lugar.
El problema de la arbitrariedad de las dos tareas implicadas la RST ya fue resuelto en parte con la creación de las Pruebas de Amplitud de Razonamiento basadas en Analogías (véase Gutiérrez-Martínez et al., 2005; García-Madruga et al., 2007), donde la palabra clave que debía almacenarse era el resultado de la realización de las analogías. De este modo, al menos se conectaba la tarea de procesamiento con la de almacenamiento. Sin embargo, aún siguen siendo tareas experimentales “no naturales” ya que el objetivo final es recordar una secuencia de palabras concretas sin otro fin ulterior, algo no habitual en las actividades cotidianas.
En nuestra propuesta, la nueva tarea ha sido diseñada para que la información almacenada sea a su vez al objetivo final de la tarea principal, la comprensión total del nuevo texto. Con esto, conseguimos que las funciones de procesamiento y almacenamiento características de la MO se realicen de forma natural en el contexto de una tarea cognitiva habitual. En este caso, el recuerdo no es el objetivo final de la tarea, sino que sirve a un fin superior y de carácter natural y habitual como es la comprensión total de un texto.
Para analizar si los procesos involucrados en CONTEX relativos al retén episódico, dependen o no de los recursos del EC, se midió el tiempo de lectura de las oraciones para confirmar si permanecía estable a pesar del aumento en el procesamiento a medida que avanza la tarea. Si en CONTEX el tiempo de lectura se mantenía estable en todos los niveles, tendríamos un indicador más de la baja intervención del EC. Esta presunción se debe a que diversos estudios han confirmado que en las pruebas de doble tarea que usan “tareas de lectura”, cuando aumenta la demanda de almacenamiento, los sujetos usan más tiempo durante el procesamiento lector, ya que deben compartir sus recursos.
Pero, además, el diseño de una tarea que creemos que mide el RE, requiere contrastarla con otras tareas de MO y con medidas de procesos cognitivos de alto nivel como la inteligencia, el razonamiento y la comprensión lectora.
Planteamiento y objetivos del estudio
El presente trabajo tiene como objetivo básico analizar si el RE puede realizar las integraciones necesarias para almacenar y mantener los “chunks” resultantes sin una participación significativa del EC. Para ello, se va a tomar como índice de medida del RE su capacidad final de almacenamiento. Se utilizará una tarea cotidiana en donde participan facilitadores contextuales y en la que existe una baja participación del EC en el proceso de “binding” al emplear textos narrativos muy sencillos que implican una comprensión semi-automatizada de los mismos. Para ello, resulta necesario contrastar si realmente el contexto de la “comprensión lectora” con textos sencillos no supone un incremento del procesamiento y por tanto implica una mínima participación del EC. Si esto es así, en consonancia con Baddeley, se puede afirmar que las funciones básicas de la MO (procesamiento y almacenamiento) resultan prácticamente independientes en este tipo de tareas donde el procesamiento está muy automatizado. En este marco se presenta una nueva tarea (CONTEX) que registra la capacidad de MO a partir de los procesos relacionados específicamente con el RE, y que además cumple con otro de los objetivos reseñados: la evaluación de la MO de un modo más natural y ecológico.
Los resultados encontrados en esta nueva tarea se contrastarán con otros dos índices de medida de la MO empleados ya en diferentes estudios, que registran principalmente la participación de los procesos más directamente relacionados con el EC (el Reading Span Test -RST- y la Prueba de Amplitud Lectora de Analogías -ANALOGY-). Así, podría decirse que la nueva tarea realiza un registro de los procesos más específicos propios del RE, mientras que las otras medidas de MO registran procesos de carácter más general relativos al EC.
Además, también se ha incluido una prueba de comprensión lectora en el estudio para contrastar la tarea específica de lectura de textos que incluye la nueva medida. Por último, para ofrecer una mayor validez de criterio de las medidas de MO, se han incluido otras dos variables cognitivas de alto nivel -inteligencia y razonamiento- ya que numerosos trabajos muestran la estrecha relación entre la MO y estas variables (véase p.ej., Cornoldi, 2006; Oberauer, Schulz, Wilhelm y SüB, 2005 en relación con la inteligencia fluida; y Kane y Engle, 2002, y García-Madruga et al., 2007, sobre razonamiento). Aunque no es el principal interés del trabajo, creemos que es importante confirmar que las tareas de MO mantienen las relaciones habituales con las medidas habituales de los procesos cognitivos de alto nivel.
Por tanto, nuestras hipótesis pueden dividirse en dos grupos. Las dos primeras relativas al objetivo primario del trabajo -analizar la relación entre el EC y el RE. Y las dos últimas hipótesis versarán en torno a la validez de las pruebas empleadas analizando si se mantienen las habituales relaciones encontradas en la literatura entre inteligencia, razonamiento y memoria operativa, tomando especial interés en el comportamiento de la nueva tarea. Así, se concretan 4 hipótesis principales:
El Retén Episódico (RE) no requiere la intervención del Ejecutivo Central (EC) en determinadas tareas. Esperamos que los textos incluidos en CONTEX no supongan un incremento significativo en la carga de procesamiento, confirmando la baja participación del EC. En este sentido, sería de esperar también que el tiempo medio de lectura entre niveles sea similar a pesar de la diferencia de dificultad entre los mismos.
Existirán diferencias entre las pruebas de MO ya que pensamos registran procesos diferentes. (a) Esperamos que ANALOGY sea la más difícil ya que implica una mayor carga de procesamiento y una mayor participación del EC. (b) Por otro lado, pensamos que CONTEX, a pesar de la demora en el tiempo y el aumento del procesamiento, será la tarea más fácil ya que se apoya en los procesos de la MLP y en la contextualización de la tarea. Se espera que se recuperen palabras que no fueran recordadas en la fase anterior (ANALOGY). (c) Aunque ANALOGY y CONTEX forman parte de la misma prueba, esperamos que las diferencias más pequeñas se encuentren entre CONTEX y RST al ser las tareas que involucran menos recursos del EC.
Las correlaciones entre las diversas medidas de MO serán positivas y significativas. No obstante, existirán diferencias entre la puntuación obtenida en CONTEX y las otras dos medidas de MO ya que registran componentes diferentes de la MO.
También se espera que las medidas de MO presenten correlaciones significativas con las variables criterio (inteligencia, razonamiento y comprensión lectora) mostrando alguna capacidad predictiva de las mismas.
Método
Participantes
La muestra estuvo formada por 60 estudiantes universitarios de primer curso de Psicología con una edad media de 24.1 años -desviación típica de 8.5 meses-. Los sujetos eran gratificados por su participación con una bonificación en su calificación de Prácticas relativa a una asignatura de Psicología Evolutiva.
De la muestra inicial fueron eliminados un total de 6 sujetos ya que no completaron todas las tareas por diferentes motivos.
Medidas
Memoria Operativa
- Reading Span Test (RST). Prueba de Amplitud Lectora en su version espalola
La prueba RST diseñada por Daneman y Carpenter (1980), aplicada en su adaptación castellana (Elosúa, Gutiérrez, García-Madruga, Luque y Garate, 1996), consiste en la lectura de una serie de frases de doce palabras de las que se debe retener en la memoria la última de ellas a fin de recuperarlas en su orden de aparición al finalizar cada serie. La tarea incluye diversos niveles que van aumentando progresivamente, desde la serie inicial en donde se presentan secuencialmente 2 frases y se requiere recordar 2 palabras clave en su orden correcto de presentación, hasta un máximo de 5 frases presentadas y el recuerdo de 5 palabras (puede verse un ejemplo del nivel 2 en el Tabla 2). Cada nivel se compone de 3 series y se puntúa como respuestas correctas el recuerdo completo de las palabras de la serie en su orden de aparición, y como respuestas incompletas el recuerdo de las palabras en desorden. Se considera error la omisión o sustitución de alguna de las palabras clave. La puntuación mínima es de 2 y la máxima de 5.8 (otros detalles sobre esta prueba, así como los criterios de puntuación completos pueden consultarse en Gutiérrez-Martínez et al., 2005). Todas las pruebas de MO se puntuaron siguiendo este mismo procedimiento.

- Prueba de Amplitud Contextualizada (PA-CONTEX)
Como ya hemos adelantado, el nuevo procedimiento diseñado que denominamos (PA-CONTEX) comprende la resolución de unas sencillas analogías de las que se debe almacenar para su posterior recuerdo las palabras que completan las analogías (véase Figura 3). Tras el primer recuerdo de estas palabras clave, el sujeto debe leer unos textos que contienen unos espacios en blanco que deben completarse nuevamente con las palabras clave almacenadas previamente, lo que resulta en la comprensión final del texto presentado. Para facilitar la identificación de los resultados en cada fase, ya hemos señalado que denominaremos “ANALOGY” a las puntuaciones obtenidas en el primer recuerdo y “CONTEX” a las puntuaciones obtenidas en el segundo recuerdo.
Para la elaboración de la tarea se realizaron previamente diversos estudios piloto a fin de confirmar que los textos por sí mismos no permitían “adivinar” o intuir las palabras claves. Además, con el propósito de lograr textos muy sencillos se utilizaron siempre palabras de baja dificultad a partir del índice de frecuencia de las palabras empleadas. Asimismo, se homogeneizó el tiempo de lectura que tardaban los sujetos en la parte introductoria de cada texto (en torno a 15 s.) y en la lectura de las frases que contenían los espacios que debían completarse con las palabras clave (5 s. aproximadamente). Los 20 segundos de demora respecto al primer recuerdo realizado en la fase 1, supone la implicación de recursos más a largo plazo que los propios que ofrece el lazo fonológico o la MCP si no se permite el refresco de la información (véase Alloway y Ledwon, 2014; Conway y Engle, 1994; Cowan et al., 1997; Cowan 2001). Así, siguiendo la propuesta de Baddeley, el mantenimiento de esta información debe suceder en el retén episódico y debe tener apoyo de la MLP. El criterio que se siguió para determinar la extensión de las frases fue igualar la longitud de las sentencias que componían los textos a las frases utilizadas en el RST en su versión en castellano (una media de 12 palabras). En el ANEXO se detalla el contenido completo de la tarea.
Inteligencia
Como índice de inteligencia general (Factor g) se tomó el Test de RAVEN (Raven, Court y Raven, 1996), en su escala avanzada universitaria.
La tarea requiere que los participantes razonen sobre las relaciones existentes entre un conjunto incompleto de formas abstractas (en una matriz de 3 x 3). El objetivo es seleccionar el elemento que completa correctamente el conjunto. La prueba consta de dos cuadernillos con sendos conjuntos de matrices de dificultad creciente. El primer cuadernillo, con 12 matrices, se utiliza a modo de entrenamiento previo. El segundo cuadernillo contiene 36 elementos, obteniéndose la puntuación directa a partir del número de ejercicios resueltos correctamente en este cuadernillo.
Razonamiento
La prueba de razonamiento utilizada fue tomada del estudio de Gutiérrez-Martínez y cols. (2004), seleccionando problemas deductivos de tipo condicional en su estructura fáctica (Si p entonces q) y contrafáctica (Si p hubiera, q habría). Fueron presentados las cuatro inferencias condicionales clásicas (Modus Ponens, Afirmación del Consecuente, Negación del Antecedente y Modus Tollens). La prueba se compone de dos ejemplos de cada enunciado, resultando un total de 16 enunciados ordenados aleatoriamente para cada sujeto (2 enunciados con sus 4 inferencias y 2 ejemplos para cada uno: 2x4x2=16). El índice de medida se obtiene a partir de la puntuación directa resultante de las respuestas correctas.
En la Tabla 3 puede verse un ejemplo con contenido de cada uno de los enunciados.

Comprensión lectora
Para medir la comprensión lectora se empleó la subtarea de comprensión lectora de textos de la prueba estandarizada para la medida de procesos lectores (PROLEC-SE) de Ramos y Cuetos (1999; véase también Cuetos, Rodríguez y Ruano, 2001). Los análisis se realizaron a partir de las puntuaciones directas obtenidas sobre las 10 preguntas de carácter inferencial, ya que en las respuestas referidas a los recuerdos literales no se produjeron errores.
Procedimiento
Se utilizó un diseño intrasujeto donde cada participante realizaba todas las tareas. Las pruebas se realizaban en dos sesiones independientes. En la primera sesión se pasaban de forma grupal las pruebas de inteligencia, razonamiento y comprensión lectora en formato lápiz y papel y en ese orden de aplicación. La segunda sesión era de aplicación individual, en donde los sujetos realizaban las dos pruebas de MO (RST y ANALOGY+CONTEX) implementadas en soporte informático mediante el programa E-Prime (Schneider, Eschman y Zuccolotto, 2002). El orden de aplicación de las dos pruebas de MO se fue alternando.
Análisis de datos
La fiabilidad de las pruebas se ha estimado en términos de “consistencia interna” mediante el coeficiente alfa de Cronbach.
La validez del constructo de la nueva tarea se evalúa analizando las diferencias existentes en el tiempo de lectura dentro de cada nivel y entre niveles, y las puntuaciones totales obtenidas en las pruebas de MO. Para analizar la existencia de diferencias significativas en rendimiento, se aplica la prueba t de Student paramétrica para muestras relacionadas.
La relación lineal esperada entre las pruebas se calculó calculando el coeficiente de correlación de Pearson entre las puntuaciones totales. Este análisis de correlación también se realizó respecto a las medidas criterio (Inteligencia general, razonamiento y comprensión de lectura) para verificar la capacidad predictiva de las pruebas estudiadas.
Para contrastar la relación entre la MO y las variables de criterio, se realizó un análisis factorial confirmatorio. Para ello, se analizó el grado de asociación entre variables mediante la “prueba de esfericidad de Bartlett” y una medida de adecuación de muestreo mediante el índice “Kaiser-Meyer-Olkin” (KMO).
Finalmente, para evaluar el poder predictivo de las medidas de MO en relación con nuestras variables de criterio, se realizaron tres análisis de regresión múltiple por etapas.
Resultados
Hipótesis 1 y 2
Para contrastar la posible independencia entre procesamiento y almacenamiento se registraron los tiempos de lectura en las frases que componen las tareas de MO a fin de confirmar si el tiempo de lectura se ve afectado por el aumento de carga en el almacenamiento. La Tabla 4, muestra los promedios de tiempos de lectura en los niveles 2 y 4 (el nivel 5 no se consideró al alcanzarlo sólo un porcentaje pequeño de los participantes). Tomando como criterio la diferencia entre estos niveles, los tiempos en RST y ANALOGY muestran un incremento significativo (RST: t = -12.26, ANALOGY: t = -6.67; gl = 53, p < .00 en ambos casos), confirmando el aumento de carga con el incremento de nivel en la tarea. Sin embargo, tal y como esperábamos, la nueva tarea (CONTEX) no muestra diferencia significativa (t = -1.90, gl = 53, p > 0.5) por lo que puede decirse que la carga de procesamiento es similar en los diferentes niveles.

Por otro lado, aunque las frases empleadas en el RST y las que componen los textos de CONTEX tienen la misma longitud, el tiempo que emplean los sujetos en la lectura en el RST (M= 4774.19mls., SD= 668.21 mls.) es significativamente menor que en CONTEX (M= 5344.91mls., SD= 940.38 mls.; (t = -5.38, gl = 53; p < .01), sugiriendo una lectura más superficial. En este sentido, la idea de que la prueba RST permite a los sujetos una lectura superficial de las frases facilitando el almacenamiento al liberar recursos del procesamiento de la lectura también se encuentra en otros estudios (véase Gutiérrez-Martínez et al., 2005 y García-Madruga et al., 2007).
Debemos reseñar que los datos de registros temporales fueron filtrados tomando como criterio de descarte aquellas puntuaciones mayores a tres desviaciones típicas por encima de la media. Del conjunto de datos, siete puntuaciones fueron sustituidas por el límite superior (la media más tres desviaciones típicas).
Con el objetivo de contrastar si los índices de medida de MO tomados registran procesos de sistemas diferentes se analizaron los estadísticos descriptivos, véase en la Tabla 5 la media (M) y desviación típica (SD) de todas las medidas. Los datos muestran que la mayor puntuación se obtiene en el RST y la puntuación más baja en ANALOGY, resultando ésta la tarea más compleja (hipótesis 2a). Estos resultados están en consonancia con los encontrados en estudios anteriores, García-Madruga y cols. (2007) y Gutiérrez-Martínez y cols. (2005). La nueva medida (CONTEX) se sitúa en un lugar intermedio con una puntuación próxima al RST, el análisis de fiabilidad refleja una buena validez interna de esta medida (Cronbach's alpha = .78).

Como esperábamos, se encontraron diferencias significativas entre todas las puntuaciones de las medidas, como refleja la comparación de medias mediante la prueba T de Student: entre RST y ANALOGY (t = 9.98, gl = 53; p < .01), entre RST y CONTEX (t = -2.51, gl = 53; p = .01), y también entre las dos medidas del procedimiento diseñado (ANALOGY y CONTEX: t = 7.44, gl = 53; p < .01). Como podemos ver, en nuestra opinión el resultado más relevante y esperado para confirmar nuestras hipótesis, es que los participantes recuerdan en la prueba CONTEX palabras que no habían recordado en ANALOGY (hipótesis 2b). Estos resultados reflejan una cierta independencia entre las dos medidas confirmando que los registros del nuevo procedimiento en su fase 1 y 2 son diferentes en algún sentido. De hecho, como esperábamos y se enunciaba en la hipótesis 2c, CONTEX obtiene puntuaciones más próximas a la prueba RST que a ANALOGY (véase Tabla 5) a pesar de formar parte de la misma prueba. Esto se debe a que esta última es más demandante del EC.
Hipótesis 3 y 4
Las intercorrelaciones entre las medidas de MO son altamente significativas lo que indica que a pesar de las diferencias en sus puntuaciones mantienen una importante base común (véase la Tabla 6). Destaca el nivel de significación (<.001) que obtiene CONTEX respecto a los otros registros de MO.
Las correlaciones entre las variables criterio reflejan la relación existente entre ellas, tal y como se preveía. En particular, la prueba de inteligencia correlaciona de forma muy significativa con razonamiento y comprensión, siendo mayor la puntuación obtenida respecto a razonamiento. Por el contrario, la relación más baja se obtiene entre razonamiento y comprensión.
Como se esperaba, las correlaciones de las pruebas de MO respecto a las variables criterio resultan en todos los casos significativas y positivas (véase la Tabla 6). De entre ellas, destaca nuevamente los datos de CONTEX ya que obtiene las correlaciones más altas en todos los casos. Respecto a la prueba de inteligencia (RAVEN) CONTEX obtiene una correlación muy superior a las otras medidas, siendo la única que obtiene una correlación altamente significativa. Frente al índice de razonamiento (RAZONAMIENTO) aunque CONTEX muestra la mayor puntuación, es muy similar a ANALOGY, mostrando el RST la correlación más baja (en consonancia con estudios previos, véase García-Madruga et al., 2007 y Gutiérrez-Martínez et al., 2005). En cuanto a la prueba de comprensión de textos (PROLEC), los datos también apoyan nuestras predicciones: el RST obtiene la correlación más baja y CONTEX presenta índices correlacionales altamente significativos.

Para profundizar en las relaciones entre la MO y las variables criterio también se llevó a cabo un análisis factorial confirmatorio mediante el método de componente principales para evaluar el ajuste relativo de un modelo de dos factores. En este modelo pensamos que deberían agruparse por un lado las tareas de MO y por otro lado las variables criterio, particularmente inteligencia y razonamiento que son tareas que registran procesos de carácter más general (de orden superior). Confirmando los estudios que señalan que son variables relacionadas pero independientes.
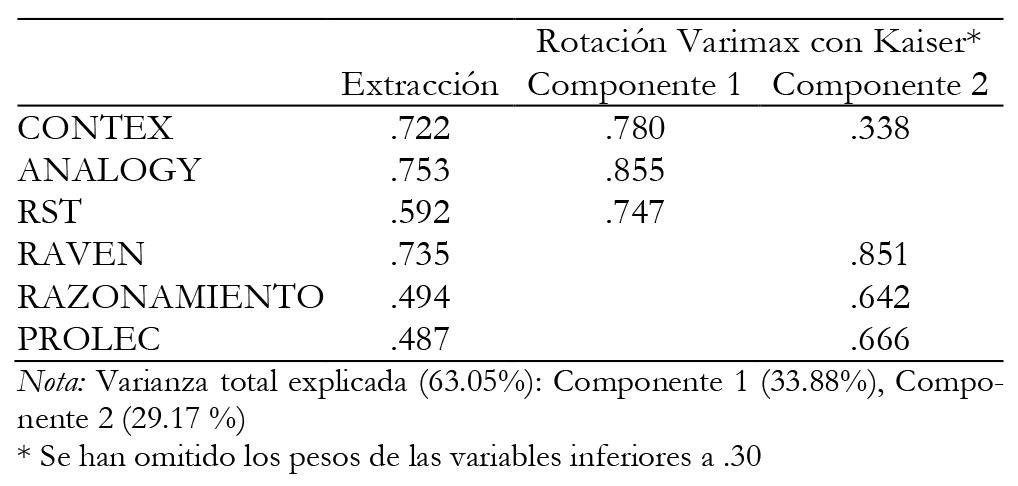
Previo al análisis factorial se analizó el grado de asociación entre las variables mediante la prueba de esfericidad de Barlett reflejando el índice de Chi cuadrado un buen ajuste de los datos (X 2 = 77.307, gl = 15, p = .00). Asimismo, la medida de adecuación de la muestra KMO (Kaiser, Meyer y Olkin) refleja una puntuación de .778 lo que aconsejó la realización del análisis factorial al ser mayor de .75.
Los dos factores del modelo generado explican algo más del 63% de la varianza (véase Tabla 7). Los análisis mediante rotación Varimax reflejan como el Factor 1 se compone básicamente de las medidas de MO y explica el 34% de la varianza, siendo CONTEX la que realiza la mayor aportación a este factor. El Factor 2 explica el 29% de la varianza, siendo RAVEN la medida que más aporta a este segundo componente. Es destacable que CONTEX muestra un peso de participación de .34 en este factor mientras las otras medidas de MO son inferiores a .15, lo que supone una mayor capacidad predictiva de CONTEX respecto a ellas.
Tabla 7: Análisis Factorial con extracción mediante análisis de componentes principales. Método de rotación: Normalización Varimax con Kaiser.
Finalmente, para evaluar la capacidad predictiva de las medidas de MO respecto a las variables criterio, se realizaron tres análisis de regresión múltiple mediante el método de pasos sucesivos empleando como variables principales las medidas de MO y como variables dependientes: inteligencia, razonamiento y comprensión. Previamente, se calcularon los índices de colinealidad (FIV) resultando inferiores a dos en todos los casos (por debajo de la puntuación de 10 citada por Kleinbaum) y mostrando índices de condición inferiores a 15 (por debajo del límite de 20 marcado por Belsley para determinar el margen de colinealidad débil).
Respecto a la medida de inteligencia, el análisis de regresión genera un modelo que explica el 16% de la varianza (F (1,52) = 9.579; p < .01; Error típ. = 4.43) siendo CONTEX la única variable introducida (B = 2.36; β = .394; p < .01). Con razonamiento, el modelo que se genera explica el 13% de la varianza (F (1,52) = 7.80; p < .01; Error típ. = .206) donde también participa sólo CONTEX (B = .099; β = .361; p < .01). Sucede lo mismo con la medida de comprensión, la regresión genera sólo un modelo que explica el 13% de la varianza (F (1,52) = 7.478; p < .01; Error típ. = 1.469) y CONTEX es la única variable que participa (B = .691; β = .355; p < .01).
Discusión and conclusiones
El principal objetivo de este estudio era explorar el Retén Episódico propuesto por Baddeley (2000) a fin de analizar su funcionamiento y la relación que mantiene con el ejecutivo central. En concreto, pretendíamos analizar si el RE es un almacén pasivo independiente cuya capacidad no se ve interferida por los procesos que el EC lleva a cabo en este espacio orientados a la integración, coordinación y agrupamiento de información proveniente de la MCP y la MLP (Baddeley et al., 2009). Los datos del presente trabajo, en su conjunto, parecen apoyar estas conclusiones.
En relación con nuestra primera hipótesis (H1) relativa a la baja carga de procesamiento en los textos de la nueva tarea, los tiempos de lectura empleados en las frases que componen los textos de CONTEX no reflejan un aumento significativo de la dificultad con el incremento de nivel, mientras que en el RST y Analogías sí se produce este aumento de la dificultad. Estos resultados parecen indicar que el incremento de la dificultad en el almacenamiento-recuerdo en estas tareas interfiere en la lectura de las frases (RST) o en el procesamiento de las analogías (ANALOGY), mientras en CONTEX gracias a un procesamiento semántico casi automático apoyado en procesos de carácter más a largo plazo no existe tal interferencia. De hecho, los resultados muestran el efecto contrario, el procesamiento de lectura concurrente ayuda a la re-activación de huellas mnésicas mediante la participación de los procesos de la MLP sin interferir en la tarea al no consumir recursos del EC. De este modo, parece confirmarse el planteamiento de Baddeley enunciado ya que el almacenamiento resulta independiente del procesamiento realizado (H1).
En este sentido, otro resultado interesante es la diferencia encontrada entre la lectura de las frases en el RST y CONTEX a pesar de que tienen la misma longitud e índice de dificultad. Que los sujetos empleen tiempos significativamente menores confirma nuestra idea de que el RST permite una lectura superficial y en CONTEX se requiere una lectura semántica, aunque de baja carga de procesamiento al ser textos muy sencillos. La comprensión de los textos de CONTEX requiere la realización de procesos específicos de integración de información (a corto y largo plazo), así como los agrupamientos necesarios para el almacenamiento y mantenimiento de esta información, es decir, las funciones propias del retén episódico.
En relación con la segunda y tercera hipótesis, las altas inter-correlaciones encontradas entre las tres pruebas de MO (H3) confirman la validez de constructo de la medida. No obstante, lo más interesante consiste en analizar estas correlaciones junto a las diferencias encontradas entre las puntuaciones en las tareas y los bajos índices de colinealidad entre ellas. En conjunto, estos resultados confirman que, aunque las medidas registran ciertos procesos compartidos, también presentan ciertas diferencias y particularidades específicas. Esto es particularmente importante en el caso de ANALOGY y CONTEX ya que ambos registros se realizan en un mismo procedimiento con dos fases. En este caso, los resultados apoyan la hipótesis de que se está registrando la capacidad de almacenamiento de la MO con la participación de diferentes procesos, aunque no es descartable que se esté registrando diferentes almacenes o sistemas.
El aumento de la puntuación en CONTEX respecto a ANALOGY apoya la idea de que la nueva medida registra una ejecución que se apoya -en mayor medida o de un modo más eficiente-, en información relevante tomada de la memoria a largo plazo que ha sido preactivada en cierto modo. Debemos recordar que en CONTEX hay una mayor cantidad de elementos a procesar —aunque este procesamiento no suponga un incremento en la carga del sistema— y la latencia temporal entre el procesamiento y el recuerdo es mayor —lo que debería propiciar un mayor desvanecimiento de las huellas mnésicas—.
No podemos obviar que la prueba de analogías se realiza antes que CONTEX lo que facilita el mantenimiento y sobreactivación de los ítems recordados en esta tarea. Sin embargo, el hecho de que existan palabras recordadas en la prueba CONTEX que no fueran recordadas en ANALOGIAS nos invita a pensar que la tarea diseñada ha posibilitado la creación de claves contextuales que permiten la recuperación de elementos desactivados o no suficientemente activados en la Fase 1 del procedimiento —es importante recordar que se contrastó que los textos por sí solos no evocan las palabras clave—. A nuestro entender, esta re-activación de ítems no recordados (olvidados) en la tarea de analogías es clave ya que parece mostrar que las condiciones experimentales de la nueva tarea, que se aproximan más a la ejecución real, permite a los participantes emplear todos sus recursos de manera semejante a como lo hacen en su vida cotidiana. Es decir, la contextualización de la tarea facilita o posibilita la participación de información relevante almacenada previamente (experiencia). Y, además, esta capacidad de almacenamiento y recuperación de información se muestra con independencia de los procesos implicados en el procesamiento lector (integración de información y agrupamiento). Con ello, además, se aportan nuevos datos sobre la capacidad del RE y su límite en torno a 4 elementos en los mejores sujetos.
Como ya hemos argumentado, el presente estudio está en consonancia con los trabajos que no encuentran interacción entre el procesamiento de carácter superficial, y los procesos de integración, almacenamiento y recuperación de información (Baddeley et al., 2009; Baddeley et al., 2011; see also Alloway, Gathercole, Willis y Adams, 2004). Por lo que proponen que la integración de palabras en agrupamientos se produce a partir de procesos automáticos que implican a la MLP y son independientes del Ejecutivo Central (Allen y Baddeley, 2009; Baddeley et al., 2009). Y, además, que el mantenimiento de estos “chunks” ya almacenados en la MO no requiere un soporte atencional importante más allá del propio para recuperar las claves (véase, p.ej., Baddeley et al., 2011; Delvenne, Cleeremans y Laloyaux, 2010; Fougnie y Marois, 2009; Gajewski y Brockmole, 2006; Johnson, Hollingworth y Luch, 2008).
En definitiva, la mejora en CONTEX muestra que el uso de los conocimientos almacenados en la MLP favorece la ejecución de la MO y permite el empleo de todos los recursos disponibles hasta alcanzar el máximo de la capacidad de almacenamiento de elementos agrupados que se sitúa en torno a 4. Así pues, resulta parsimonioso pensar que el RE sea el espacio mental pasivo e independiente empleado para almacenar los ítems, y que la recuperación de los agrupamientos depende de las claves contextuales que se empleen para ello. Lo que converge en cierto modo con los modelos de Engle y Cowan (Engle, 2001, 2002; Cowan, 1999, 2005; Unsworth y Engle, 2007) que proponen un único almacén con diferentes niveles de activación. No obstante, tampoco se puede descartar la posibilidad de que estuviéramos registrando dos almacenes pasivos diferentes, uno más a corto plazo (el registrado en RST y ANALOGY) y otro más a largo plazo acorde con el RE reflejado en CONTEX, en línea con la propuesta clásica de ejecución experta de Ericsson y Kintch (1995).
Por último, el presente estudio también aporta nuevos datos al debate en torno a las relaciones que se han venido estableciendo en diversos trabajos entre la MO y diferentes habilidades cognitivas de orden superior como el razonamiento, la comprensión lectora y la inteligencia fluida. Los datos muestran nuevamente como el rendimiento en las tareas de MO constituye un buen predictor del nivel de los sujetos en estas actividades cognitivas. Pero resulta destacable como la tarea que muestra mayor capacidad predictiva es CONTEX, ya que obtiene correlaciones muy similares y altamente significativas con a las tres variables, y es la única medida que resulta significativa en los análisis de regresión.
En cierto sentido estos resultados también apoyan la hipótesis de que CONTEX está registrando el RE, ya que, al requerir de la participación de la información almacenada en la MLP, es en este espacio mental en el que se llevan a cabo los procesos cognitivos implicados tanto en la comprensión de textos, como en la resolución de problemas deductivos y en la resolución de los problems de matrices que componen la prueba de inteligencia fluida aplicada. Esto podría explicar la similitud de resultados obtenidos por CONTEX frente a las tres variables criterio, tanto en las correlaciones como en el porcentaje de varianza explicada en cada una de ellas. Con ello, además de confirmarse la validez de constructo antes mencionado, también se confirma la validez de criterio de CONTEX.
Sin embargo, parece necesario que en próximos estudios se diseñen otras tareas en las que se iguale el procesamiento y los procesos específicos de integración y agrupamiento, a fin seguir evaluando la capacidad de almacenamiento del RE. Sería necesario también comprobar las diferencias entre la realización de la prueba de CONTEX tras la de ANALOGY, tal y como se ha realizado en este estudio, y la realización de CONTEX sin pedir previamente el recuerdo de las palabras-solución de la prueba de analogías. Por último, se debería tratar de aumentar la muestra y extender la evaluación a sujetos en edad escolar, ya que la capacidad predictiva mostrada por CONTEX respecto a las variables criterio hace prever también buenas relaciones respecto a variables como el rendimiento académico, con todo lo que ello conlleva desde el punto de vista aplicado.
References
Allen, R.J., & Baddeley, A.D. (2009). Working memory and sentence recall. In A. Thorn, & M. Page (Eds.), Interactions between short-term and long-term memory in the verbal domain (pp. 63-85). Hove, East Sussex, UK: Psychology Press. [ Links ]
Allen, R.J., Baddeley, A.D., & Hitch, G.J. (2006). Is the binding of visual features in working memory resource-demanding? Journal of Experimental Psychology: General, 135, 298-313. [ Links ]
Allen, R.J., Baddeley, A.D., & Hitch, G.J. (2014). Evidence for two attentional components in visual working memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 40(6), 1499-1509. [ Links ]
Alloway, T.P., & Ledwon, F. (2014). Working memory and sentence recall in children. International Journal of Educational Research, 65, 1-8. [ Links ]
Alloway, T.P., Gathercole, S.E., Willis, C., & Adams, A.M. (2004). A structural analysis of working memory and related cognitive skills in young children. Journal Experimental Child Psychology, 87(2), 85-106. [ Links ]
Anderson, J.R., Reder, L.M., & Lebière, C (1996). Working memory: activation limitations on retrieval. Cognitive Psychology, 30, 221-256. [ Links ]
Baddeley, A.D. (1986). Working memory. Oxford, UK: Oxford University Press. [ Links ]
Baddeley, A.D (2000). The episodic buffer: A new component of working memory? Trends in Cognitive Sciences, 4(11), 417-423. [ Links ]
Baddeley, A.D. (2007). Working memory, thought, and action. Oxford, UK: Oxford University Press. [ Links ]
Baddeley, A.D. (2010). Working memory. Current Biology, 20, 136-140. [ Links ]
Baddeley, A.D. (2012). Working memory: Theories, models, and controversies. Annual Review of Psychology, 63, 1-29. [ Links ]
Baddeley, A.D., & Hitch, G. (1974). Working memory. In G.A. Bower (Ed.), The psychology of learning and motivation (Vol. 8, pp. 47-89). New York: Academic. [ Links ]
Baddeley, A.D., & Logie, R.H. (1999). Working memory: The multi-component model. In A. Miyake y P. Shan (Eds.), Models of working memory: Mechanisms of active maintenance and executive control. Cambridge: Cambridge University Press. [ Links ]
Baddeley, A.D., Hitch, G.J., & Allen, R.J. (2009). Working memory and binding in sentence recall. Journal of Memory and Language, 61, 438-456. [ Links ]
Baddeley, A.D., Allen, R.J., & Hitch, G.J. (2011). Binding in visual working memory: The role of the episodic buffer. Neuropsychologia, 49, 1393-1400. [ Links ]
Barrouillet, P., Bernardin, S., Portrat, S., Vergauwe, E., & Camos, V. (2007). Time and cognitive load in working memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 33, 570-585. [ Links ]
Brener, R. (1940). An experimental investigation of memory span. Journal of Experimental Psychology, 26, 467-482. [ Links ]
Cain, K., Oakhill, J., & Bryant, P. (2004). Children's reading comprehension ability: Concurrent prediction by working memory, verbal ability, and component skills. Journal of Educational Psychology, 96(1), 31-42. [ Links ]
Carretti, B., Borella, E., Cornoldi, C., & De Beni, R. (2009). Role of working memory in explaining the performance of individuals with specific reading comprehension difficulties: A meta-analysis. Learning and Individual Differences, 19(2), 246-251. [ Links ]
Case, R. (1985).Intellectual development: Birth to adulthood. New York: Academic Press. [ Links ]
Conway, A.R.A., & Engle, R.W. (1994). Working memory and retrieval: A resource dependent inhibition model. Journal of Experimental psychology: General, 123, 354-373. [ Links ]
Cornoldi, C. (2006). The contribution of cognitive psychology to the study of human intelligence. European Journal of Cognitive Psychology, 18(1), 1-17. [ Links ]
Cowan, N. (1999). An embedded-processes model of working memory. In A. Miyake & P. Shah (Eds.), Models of working memory: Mechanisms of active maintenance and executive control (pp. 62-101). Cambridge, UK: Cambridge University Press. [ Links ]
Cowan, N. (2001). The magical number 4 in short-term memory: A reconsideration of mental storage capacity. Behavioral and Brain Sciences, 24, 87-185. [ Links ]
Cowan, N. (2005). Working memory capacity. New York: Psychology. [ Links ]
Cowan, N., Wood, N.L., Nugent, L.D., & Treisman, M. (1997). There are two word length effects in verbal short-term memory: Opposed effects of duration and complexity. Psychological Science, 8, 290-295. [ Links ]
Cuetos, F., Rodríguez, B., & Ruano, E. (2001). PROLEC-SE. Procesos Lectores. Madrid: TEA. [ Links ]
Daneman, M., & Carpenter, P.A. (1980). Individual differences in working memory and reading. Journal of Verbal Learning and Verbal Behavior, 19(4), 450-466. [ Links ]
Daneman, M., & Merikle, P.M. (1996). Working memory and comprehension: A meta-analysis. Psychonomic Bulletin & Review, 3(4), 422-433. [ Links ]
Delvenne, J.F., Cleeremans, A., & Laloyaux, C. (2010). Feature bindings are maintained in visual short-term memory without sustained focused attention. Experimental Psychology, 57(2), 108-116. [ Links ]
Elosúa, M.R., Gutiérrez, F., García-Madruga, J.A., Luque, J.L. & Gárate, M. (1996). Adaptación española del “Rea- ding Span Test” de Daneman y Carpenter. Psicothema, 2, 383-395. [ Links ]
Engle, R.W. (2001). What is working memory capacity? En H.L. Roediger, J.S. Naime, I. Neath, & A.M. Supremant (Eds.), The nature of remembering: Essays in honor of Robert G. Crowde (pp. 297-314). Washington, DC: American Psychological Association. [ Links ]
Engle, R.W. (2002). Working memory capacity as executive attention. Current Directions in Psychological Science, 11(1), 19-23. [ Links ]
Ericsson, K.A., & Kintsch, W. (1995). Long-term working memory. Psychological review,102(2), 211. [ Links ]
Fougnie, D., & Marois, R. (2009). Attentive tracking disrupts feature binding in visual working memory. Visual Cognition, 17, 48-66. [ Links ]
Gajewski, D.A., & Brockmole, J.R. (2006). Feature bindings endure without attention: Evidence from an explicit recall task. Psychonomic Bulletin & Review, 13, 581-587. [ Links ]
García-Madruga, J.A., Elosúa, M.R., Gil, L., Gómez-Veiga, I., Vila, J.O., Orjales, I., Contreras, A., Rodríguez, R., Melero, M.A., & Duque, G. (2013). Reading Comprehension and Working Memory's Executive Processes: An Intervention Study in Primary School Children. Reading Research Quarterly, 48(2), 155-174. [ Links ]
García-Madruga, J.A, Gómez-Veiga, I. & Vila-Chaves, J.O. (2016). Executive functions and the improvement of thinking abilities: The intervention in reading comprehension. Frontiers in Psychology. 7, pp. 58-73. [ Links ]
García-Madruga, J. A., Gutiérrez, F., Carriedo, N., Luzón, J. M., & Vila, J. O. (2007). Mental models in propositional reasoning and working memory's central executive. Thinking and Reasoning, 13(4), 370-393. [ Links ]
Gutiérrez, F., García-Madruga, J.A., Carriedo, N., Vila, J.O., & Luzón, J.M. (2005). Dos pruebas de Amplitud de Memoria Operativa para el Razonamiento (Two tests of Operating Memory Width for Reasoning). Cognitiva, 17(2), 183-203. [ Links ]
Hannon, B., & Daneman, M. (2001). A new tool for measuring and understanding individual differences in the component process of reading comprehension. Journal of Educational Psychology, 93(1), 103-128. [ Links ]
Hannon, B., & Daneman, M. (2004). Shallow semantic processing of text: An individual-differences account. Discourse Processes, 37(3), 187-204. [ Links ]
Johnson, J.S., Hollingworth, A., & Luck, S.J. (2008). The role of attention in the maintenance of feature bindings in visual short-term memory. Journal of Experimental Psychology: Human Perception and Performance, 34, 41-55. [ Links ]
Just, M.A., & Carpenter, P.A. (1992). A capacity theory of comprehension. Psychological Review, 99(1), 122-149. [ Links ]
Kane, M.J., & Engle, R.W. (2002). The role of prefrontal cortex in working-memory capacity, executive attention, and general fluid intelligence: An individual-differences perspective. Psychonomic Bulletin & Review, 9(4), 637-671. [ Links ]
Kane, M.J., Hambrick, D.Z., Tuholski, S.W., Wilhelm, O., Payne, T.W., & Engle, R.W. (2004). The generality of working-memory capacity: A latent-variable approach to verbal and visuospatial memory span and reasoning. Journal of Experimental Psychology: General, 133(2), 189-217. [ Links ]
Miller, G. A. (1956). The magical number seven, plus or minus two: some limits on our capacity for processing information. Psychological Review, 63(2), 81-97. [ Links ]
Miyake, A., Friedman, N.P., Emerson, M.J., Witzki, A.H., & Howerter, A. (2000). The unity and diversity of executive functions and their contributions to complex “frontal lobe” tasks: A latent variable analysis. Cognitive Psychology, 41(1), 49-100. [ Links ]
Miyake, A., & Shah, P. (1999). Toward unified theories of working memory: Emerging general consensus, unresolved theoretical issues, and future research directions. In A. Miyake & P. Shah (Eds.), Models of working memory (pp. 442-481). New York: Cambridge University Press. [ Links ]
Oberauer, K., Schulze, R., Wilhelm, O., & Süß, H.-M. (2005). Working memory and intelligence-their correlation and their relation: Comment on Ackerman, Beier, and Boyle (2005). Psychological Bulletin, 131(1), 61-65. [ Links ]
Raven, J.C., Court, J.H., & Raven, J. (1996). Raven matrices progresivas. Escalas: Color (CPM), General (SPM), Superior (APM) (Raven progressive matrice). Manual. Madrid: TEA Ediciones S.A. [ Links ]
Schneider, W., Eschman, A., & Zuccolotto, A. (2002). E-Prime (Version 2.0). (Computer software and manual). Pittsburgh, PA Psychology Software Tools Inc. [ Links ]
Turner, M.L., & Engle, R.W. (1989). Is working memory capacity task dependent? Journal of Memory and Language, 28, 127-154. [ Links ]
Tulving, E., & Patkau, J.E. (1962). Concurrent effects of contextual constraint and word frequency on immediate recall and learning of verbal material. Canadian Journal of Psychology, 16, 83‑95. [ Links ]
Unsworth, N., & Engle, R.W. (2007). The nature of individual differences in working memory capacity: Active maintenance in primary memory and controlled search from secondary memory. Psychological Review, 114(1), 104-132. [ Links ]
Vukovic, R.K., & Siegel, L.D. (2006). The role of working memory in specific reading comprehension difficulties. In T.P. Alloway & S.E. Gathercole (Eds.), Working memory and neurodevelopmental disorders (pp. 89-112). New York: Psychology. [ Links ]
Recibido: 02 de Octubre de 2018; Revisado: 24 de Junio de 2019; Aprobado: 16 de Noviembre de 2019
 This is an open-access article distributed under the terms of the Creative Commons Attribution License
This is an open-access article distributed under the terms of the Creative Commons Attribution License