










Mi SciELO
 Servicios personalizados
Servicios personalizadosServicios Personalizados
Revista
Articulo
 Inglés (pdf)
Inglés (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares en
SciELO
Similares en
SciELO -
 Similares en Google
Similares en Google
Compartir

 Permalink
PermalinkThe European Journal of Psychology Applied to Legal Context
versión On-line ISSN 1989-4007versión impresa ISSN 1889-1861
The European Journal of Psychology Applied to Legal Context vol.5 no.1 Madrid ene. 2013
The reliability of identification evidence with multiple lineups
Melanie Sauerland*, Anna K. Stockmar**, Siegfried L. Sporer** and Nick J. Broers*
*Maastricht University (The Netherlands)
**University of Giessen (Germany)
ABSTRACT
This study aimed to establish the diagnostic value of multiple lineup decisions made for portrait, body, and profile lineups, including multiple target/suspect choices, rejections, foil choices, and don't know answers. A total of 192 participants identified a thief and a victim of theft from independent simultaneous target-present or target-absent 6-person portrait, body and profile lineups after watching one of two stimulus films. As hypothesized, multiple target/suspect choices had incriminating value whereas multiple rejections, foil choices, and don't know answers had mostly exonerating value. For suspect choices, the combination of all three lineup modes consistently elicited high diagnosticities across targets. Combinations of non-suspect choices (rejections, foil choices, or don't know answers) were less successful and the different combinations showed less consistency in terms of diagnosticity. It was concluded that the use of multiple lineups, such as different facial poses and different aspects of a person should be particularly beneficial in three situations: if a witness only saw the perpetrator from a pose different than the frontal view normally used for lineups; if one or more witnesses saw the perpetrator from more than one perspective; and if different witnesses saw the perpetrator from different perspectives.
Key words: multiple lineups; change of view; rejections, foil selections; don't know answers.
RESUMEN
El estudio tuvo como objetivo establecer el valor diagnóstico de decisiones múltiples en ruedas fotográficas de identificación de la cara, cuerpo y de perfil, que implican múltiples elecciones del objetivo/sospechoso; rechazos, elecciones de cebos, y respuestas "no sé". Un total de 192 participantes identificaron a un ladrón y a la víctima de un robo en ruedas independientes y simultáneas de perfil, cuerpo o cara de 6 personas con el objetivo presente o ausente. En consonancia con las hipótesis planteadas, elecciones múltiples del objetivo/sospechoso tenían valor incriminatorio mientras que múltiples rechazos, elecciones de cebos y respuestas no sé, generalmente tenían valor exonerante. En las elecciones del sospechoso, la combinación de los tres formatos de ruedas de identificación dio lugar, de modo consistente, a diagnósticos correctos. Las combinaciones de decisiones de no-sospechosos (rechazos, elecciones de cebos, o respuestas no sé) resultaron menos exitosas, al tiempo que las diferentes combinaciones mostraron una menor consistencia en el diagnóstico. Se concluye que el uso de múltiples ruedas de identificación, tales como diferentes poses faciales y diferentes aspectos de una persona deberían ser particularmente beneficiosos en tres situaciones: si un testigo sólo vio al perpetrador desde una posición diferente a la frontal que es la forma de presentación característica de las ruedas; si uno o más testigos vieron al perpetrador desde más de una perspectiva; y si diferentes testigos vieron al perpetrador desde perspectivas diferentes.
Palabras clave: ruedas de identificación múltiples; cambio de perspectiva; rechazos; elección de cebos; respuestas no sé.
Introduction
In eyewitness identifications, system or control variables refer to those factors that the judicial system and police forces have an influence on (Wells, 1978). Therefore, they are of particular interest with regard to legal policy. Among the most studied control variables are pre-lineup instructions (Clark, 2005), the method for selecting foils (Wells, Rydell, & Seelau, 1993) as well as the lineup presentation mode (Steblay, Dysart, & Wells, 2011). A relatively new system variable is the usage of multiple lineups. Here, witnesses identify different aspects of a target (i.e., face, body, voice, clothing) in independent lineups which omit all other aspects (i.e., faces cannot be seen in body lineups). The rationale behind this approach is that the probability that a witness identifies a suspect by chance is potentially decreased with every additional aspect that has to be identified. In a six person lineup this probability decreases from 1/6 with only one aspect to 1/36 with two independent lineups of two aspects, and to 1/216 with three independent lineups of three aspects. The same improvement in diagnosticity can be achieved when there are one, two or three witnesses who view just a facial lineup (see Clark & Wells, 2008). However, multiple witnesses are often not available. The idea that the performance in different lineups regarding different aspects of a person is independent from each other was supported by Sauerland and Sporer (2008) who found no association between performance in portrait, profile, body, and shopping bag lineups. The probative value of lineups can be determined with the diagnosticity ratio (DR; see Wells & Olson, 2002) and conditional probabilities (see Clark, Howell, & Davey, 2008). The DR is defined as the ratio of correct to incorrect decisions. For target/suspect choices this refers to the ratio of hits (target choices) in target-present (TP) lineups to false alarms (suspect choices) in target-absent (TA) lineups. Similarly, for rejections, foil choices and don't know answers, the DR is the ratio of the referring decision type in TA lineups to those in TP lineups (Clark et al., 2008; Clark & Wells, 2008; Wells, Charman, & Olson, 2005). When DR equals 1, the lineup is neither diagnostic of the guilt nor of the innocence of the suspect. Conditional probabilities range between 0 and 1 and refer to the probability that a suspect is guilty, given an identification, or is innocent, given the witness's response was a rejection, foil choice or don't know answer (Clark et al., 2008). A DR of 1 corresponds to a conditional probability of .50.
Research on multiple lineups has shown that this method has the power to increase diagnosticity and therefore to increase the probative value of identification evidence using face, body, voice, clothing and/or accessory lineups (Lindsay, Wallbridge, & Drennan, 1987; Pozzulo, Dempsey, & Gascoigne, 2009; Pryke, Lindsay, Dysart, & Dupuis, 2004; Sauerland & Sporer, 2008). For example, in the first study on multiple lineups, Lindsay et al. (1987) reported a DR of 13.6 for target/suspect choices for the combination of face and clothing lineups. For participants who only chose the suspect's face, but not the clothing the DR was only 1.9. Thus, when a witness chose a face and then chose the matching clothing originally worn by that person in a second independent lineup, it was 13.6 times more likely that the identified person actually was the target than that he was an innocent suspect. In contrast, if a participant chose a face, but failed to choose the matching clothing in a second lineup, it was only 1.9 times more likely that the identified person actually was the target than that he was an innocent suspect. Pryke et al. (2004) as well as Sauerland and Sporer (2008) replicated the success of multiple lineup administrations with various kinds of lineups.
Not only target/suspect choices, but also lineup rejections, foil choices and don't know answers can be diagnostic of guilt or innocence, respectively (Wells & Olson, 2002; but see Clark et al., 2008). For lineup rejections, Sauerland and Sporer (2008) reported higher DRs for the combinations of portrait and body as well as for profile and shopping bag lineups than for each lineup type by itself. The effects for rejections were much smaller than for target/suspect choices though. For foil choices, only the portrait lineup was diagnostic, and combinations were not more diagnostic than individual lineups. Note that there seems to be an exception with regard to foil choices when foils are selected based on their similarity to the suspect (Clark et al., 2008): in these cases foil choices appear to be non-diagnostic, or even diagnostic of guilt, rather than of innocence. To our knowledge, the probative value of multiple don't know answers has never been studied.
It was the aim of the present study to replicate earlier findings with regard to multiple target/suspect choices, rejections, and foil choices. Furthermore, the study for the first time examines the extent to which multiple don't know answers are diagnostic. Thus the probative value of all four possible lineup decision outcomes will be established. It was expected that lineup combinations would be more diagnostic than individual lineups. Furthermore, it was hypothesized that target/suspect choices would be diagnostic of guilt, whereas rejections, foil choices and don't know answers would be diagnostic of innocence.
Method
Participants
One-hundred-and-ninety-two participants (108 male, 84 female; age 15-63, Mdn = 23 years) participated in this study. They were university of applied sciences students (50.0%), university students (15.1%), high-school students (13%), worked in academic (6.8%), mercantile (2.6%), social (2.1%), or other professions (9.9%), or were housewives/-husbands (0.5%).
Design
A 2 (film: 1 vs. 2) x 2 (target-presence: TA vs. TP) x 2 (target-presence: TA vs. TP) mixed design with target-presence being both a between- and a within-subjects factor was employed. Fifty percent of the participants viewed the lineups of target 1 (thief) as TP and the lineups of target 2 (victim) as TA. The other half of the participants viewed TA thief and TP victim lineups. Thus, each participant viewed a total of 6 lineups (2 targets in 3 modes each). Target-presence for portrait, body and profile lineups was held constant for each target. That is, if a participant viewed a TP portrait lineup of the thief, the body and profile lineups would also be TP. The reason for this procedure is that diagnosticity can only be computed when all modes are presented in the same target-presence condition for a given participant. Limiting the design this way also makes sense regarding ecological validity as in real lineups all three photographs of suspects would always be those of the real perpetrator or not.
Materials
Photo lineups
Target persons were four (2 female, 2 male) students (age 20-33). For the facial photographs, jewelry, eyeglasses and hair accessories were taken off and hair was worn loose. On the body photographs, each lineup member wore different long sleeve clothing which also differed from the clothing worn in the stimulus film. The head was blotched out with an opaque oval covering the head and neck.
Lineups consisted of six color photographs (faces: neck up; bodies: shoulders down) simultaneously presented on a 15" computer screen at a color depth of 16.7 million colors and a resolution of 1024 x 768 pixels. The photos were arranged in two rows of three pictures each, with "not present" and "don't know" options on the side.
The position (1-6) of the thief/suspect in the thief's portrait lineup was varied systematically, occurring equally often at each position. The position of targets/replacements in the victim lineups was held constant between participants but varied across lineup types.
Lineup construction
For the portrait face lineup, all foils, including the replacement, fit the general description of the target persons (Wells et al., 1993) as determined by a pilot study with 55 mock witnesses. Following Pryke et al.'s (2004) procedure, little effort was made to select foils on the basis of similarity to features other than facial as witnesses usually do not provide detailed descriptions about the target's body (Brown, Lloyd-Jones, & Robinson, 2008; Meissner, Sporer, & Schooler, 2007). Also, from a practical perspective, it is unlikely that the police engage in the time consuming procedure of matching foils to the suspect with regard to more than general similarity unless there are some unusual features, which was not the case for our targets (see Pryke et al., 2004).
Note the accuracy for body lineups by themselves tends to be low. However, it has been shown (Pryke et al., 2004; Sauerland & Sporer, 2008) that the choice of a suspect body in addition to his/her portrait occurs much more often in TP lineups than in TA lineups (i.e., for accurate decisions). Therefore, the inclusion of body lineups was considered appropriate.
Stimulus films
Two different stimulus films showed the theft of a wallet in a student cafeteria and lasted for 5:05 min and 3:15 min, respectively. Four different amateur actors (one woman and three men) participated in each film. In film 1 the thief was male, the victim female, in film 2 it was the other way around (but with different actors). Each person could be seen for at least 89 seconds, and there were close-ups of all targets varying between 2 and 12 s. All targets could be seen from frontal and side views.
The action can be described as follows: three students sit together talking about the summer break. After a while, a fourth student (the thief), unfamiliar to the former three, sits down next to them and reads a book. When the future victim gets up to get some coffee, the thief steals his/her wallet without the other two students noticing. After leaving the table, a close-up view of the perpetrator going through the wallet follows. When the victim returns s/he realizes that the wallet was stolen.
Procedure
All instructions and lineup presentations were programmed with SuperLab 1.75 (www.cedrus.com). Participants were randomly assigned to the experimental conditions. They were informed that the experiment dealt with witness statements and were asked to pay attention to the film as they would be asked questions about it afterwards. The topic of person identification was not mentioned. After viewing one of the two films participants completed a 30-minutes filler task consisting of 40 general knowledge questions. They then viewed portrait, body and profile lineups of the thief and the victim. The thief lineups were always presented first, followed by the victim lineups. The instructions for participants included the information that they were now asked to identify the thief/the person who the wallet was stolen from, respectively, as well as the warning that the target may or may not be present in each lineup.
To allow for a comparison of the quality of the evidence that would be obtained from the standard police procedure (portrait lineup alone) with the multiple lineup procedure, the portrait lineup was always presented first. The sequence of the following two lineups (body and profile) was also not counterbalanced to avoid that both facial lineups were presented directly after another.
Data analyses
Data were collected for both the thief and the victim in order to obtain two data points rather than one per participant. This is consistent with other studies (Brewer, Weber, Clark, & Wells, 2008; Brewer & Wells, 2006). Note, however, that differences in the outcome may result either from the different roles that the targets played or other differences between targets (distinctiveness, sex, age, etc.). Accordingly, separate analyses were carried out for the thieves and victims.
First, the associations of identification performance and choosing rates between the lineups will be reported. Hereafter, the conditional probabilities for the three lineup types are presented separately (ignoring other decisions), followed by those for multiple lineup decisions (i.e., taking other decisions into account).
Results
Correlations of identification accuracy and choosing
The first analyses looked at how performance in the three different lineup types was associated (e.g., do people who make an accurate portrait lineup decision also make an accurate body/profile lineup decision?). A small correlation between lineup performances would support the notion that performance in multiple lineups, using different aspects of a person is independent. Further analyses focused on whether making a choice in one lineup mode was associated with making a choice in another lineup mode (i.e., is there a general tendency to choose/reject?). To answer these questions correlations of accuracy in portrait, body, and profile lineups were computed for each target. The same was done for choosing. The r-values can be found in Table 1. Not surprisingly, there was a strong association of the two facial lineups looking at both accuracy and choosing for thieves and victims. Thus, the two facial lineups were not independent. Keep in mind that both facial lineups appeared in the same target-presence condition (i.e., both TP or both TA) in order to allow for estimates of conditional probabilities. Therefore, it might have been expected that participants tended to make consistent decisions across these two lineups. That does not, however, preclude increased diagnosticity as a result of multiple selections. Correlations of both facial lineups with the body lineups were small to medium (.004 < r2 < .068) for both accuracy and choosing (cf. Cohen, 1988). Thus, our data support the notion that identification performance concerning different aspects of a person is relatively independent from one another.

Diagnosticity of lineups
For the main analysis, conditional probabilities (percent guilty) that the suspect is the thief, given that one, two or three of the three (portrait, body, profile) lineup decisions were suspect choices, rejections, foil choices or don't know answers were computed. The conditional probabilities for the victims were obtained analogously and for the sake of clarity of exposition the same terms will be used for victim choices, although the victim is, of course, not a suspect.
As choosing rates for a single foil can vary widely and can have a great impact on the results obtained (see Pryke et al., 2004; Sauerland & Sporer, 2008), results will be reported for two different methodologies. This is to make the results comparable to other studies and to monitor in what way the methodology used can have an influence on the results. Specifically, results for the foil chosen most often ("worst case") and the average across all foils ("average") will be reported. TA lineup foil choices were computed by multiplying all choices with 5/6, that is, multiplying by 5 foils, divided by k = 6 lineup members (five foils plus the suspect).
Diagnosticity as a function of specific lineup mode
Table 2 displays the frequencies of hits, false alarms, correct and false rejections, foil choices and don't know respo nses obtained. These were used to compute the % guilty values presented in Tables 3 and 4. Note that this includes all decisions (N = 192 for both thief and victim lineups), regardless of preceding or successive decisions concerning a target. Percentage guilty represents the proportion of suspects that would be guilty if the procedure of multiple lineups was applied to a large number of cases, with a 50% base rate of both TP and TA lineups. It was hypothesized that suspect identifications are diagnostic of guilt, whereas all other decision types are diagnostic of innocence (see Clark et al., 2008; Clark & Wells, 2008; Wells & Lindsay, 1980; Wells& Olson, 2002).

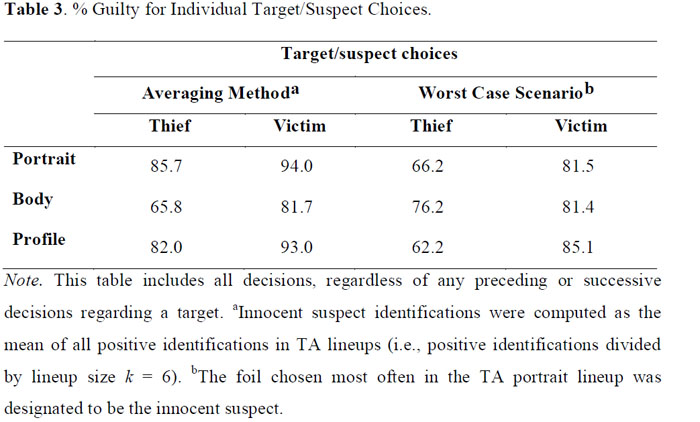

From Tables 3 and 4, one can conclude that, as expected, target/suspect choices were indicative of suspect guilt, and rejections (with one exception), foil choices and don't know answers were indicative of innocence. This supports the hypothesis that these decision types are more likely when the target is absent than when s/he is present. This is of particular interest as these decision outcomes are often not attributed much probative value and are hence often ignored, even by defense attorneys (Clark & Wells, 2008).
Furthermore, the probative value of portrait lineups was generally similar to the probative value of profile lineups across both thieves and victims and across both methods of establishing innocent suspect choices. The probative value of decisions concerning the body lineups tended to be weakest, although there were exceptions.
Multiple lineup decisions
Percent guilty for multiple lineup choices and rejections can be found in Tables 5 (target/suspect choices) and 6 (rejections, foil choices, and don't know answers). Unlike Tables 3 and 4, Tables 5 and 6 account for both preceding and successive decisions. For example, the conditional probability for the cell indicating portrait target/suspect choices was computed by eliminating those cases in which the same lineup member had additionally been chosen in profile and/or body lineups. Therefore, the values differ from those presented in Tables 3 and 4. For instance, choosing the thief from a portrait lineup, regardless of other decisions made, resulted in 85.7% guilty (Table 3, averaging method). Eliminating participants who not only made a thief identification, but also chose the thief from body and/or profile lineups, however, led to 76.6% guilty. In the following, the results for multiple lineup decisions for target/suspect choices, rejections, foil choices, and don't know answers will be elaborated on successively, followed by inferential tests using GEE analyses.


Target/suspect choices
For target/suspect choices, the conditional probabilities of each lineup by itself were in general relatively low, often actually being non-diagnostic of guilt. As expected, most lineup combinations were more diagnostic than each lineup mode by itself, and the combination of all three lineups was highly successful for both thieves and victims (88.9 - 99.0% guilty), regardless of method chosen to establish innocent suspects choices.
Lineup rejections
No consistent result pattern was found for lineup rejections. While the portrait lineup alone was most diagnostic of innocence (38.2% guilty) for the thief, the combinations of portrait and body as well as all three lineups were highly diagnostic of innocence for the victim (0.0% guilty). Unexpectedly, lineup combinations were not necessarily more diagnostic than individual lineups.
Foil choices
Looking at foil choices, the combinations of portrait and body lineups (0.0% guilty) as well as all three lineups (0.0 - 18.8% guilty) were highly diagnostic of innocence for both thieves and victims.
Don't know answers
No consistent result pattern emerged for don't know answers. While the combination of profile and body lineups was most successful for thieves (0.0% guilty), the portrait and profile lineups alone were most successful for the victims (0.0% guilty).
Establishing the benefit of additional lineups
The key issue addressed in the present research was whether suspect identifications, lineup rejections, foil choices and don't know answers in lineups in addition to the portrait lineup would be more indicative of guilt/innocence than decisions based on the portrait only. Therefore, the DRs for the portrait only were compared with the DRs for portrait plus one (body or profile) or plus two (body and profile) additional lineups. For independent observations, a simple test of the equality of the DRs of the portrait vs. the portrait plus one/two lineups can be calculated using a chi-square test for the equality of two population distributions (e.g., Pryke et al., 2004; Sauerland & Sporer, 2008). However, as our DRs are based on repeated observations across four different targets (across two different films), conventional chi-square tests were unsuitable. Rather, a regression methodology known as generalized estimating equations (GEE) was required. This method, which can be used for binary as well as for continuous outcome variables, gives appropriate estimates of the standard errors of the regression parameters, by using weighted observations that reflect the fact that not all N observations are independent (Hanley, Negassa, Edwardes, & Forrester, 2003). Note that odds ratios are suggested as the method of choice for proportions by any standard textbook on frequencies and proportions (e.g., Fleiss, Levin, & Paik, 2003) as well as the standard literature on meta-analyses (Cooper, Hedges, & Valentine, 2009; Lipsey & Wilson, 2001; Sporer & Cohn, 2011).
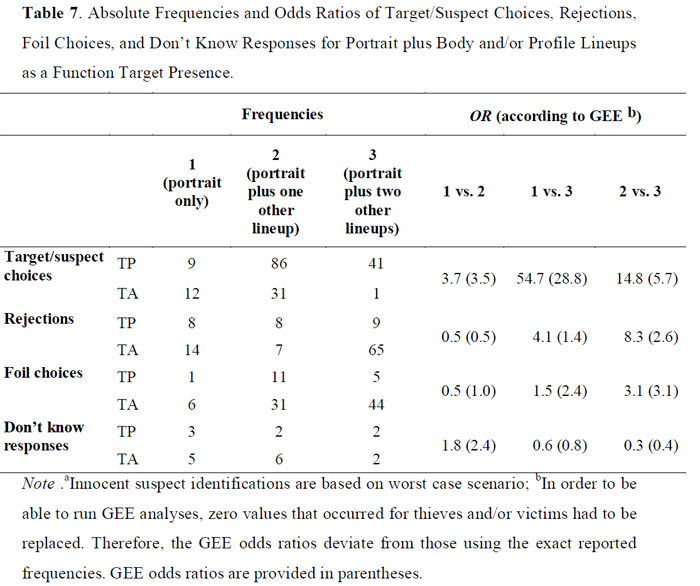
Due to computational reasons, the frequencies used for these analyses had to be based on the worst case scenario. Specifically, GEE analyses require the input of individual responses and thus cannot be run with an average of individual responses. As the averaging method mostly results in more pronounced effects (see Table 3), the estimated odds ratios might underestimate the true parameter values, rendering significance tests somewhat conservative. In the following, the results of the GEE analyses for target/suspect choices, rejections, foil choices, and don't know answers are described. For each decision outcome, the diagnosticities of 1 vs. 2 lineups, 1 vs. 3 lineups and 2 vs. 3 lineups were tested against each other. Note that interactions were non-significant, unless otherwise stated. Thus, there were no significant differences in the results as a function of target (role). Table 7 presents the proportion of witnesses who identified just the suspect's portrait or the suspect's portrait and one or two other aspects of the person (body and/or profile) in TA and TP lineups.
Target/suspect choices
For target/suspect choices, the GEE analyses revealed that two lineups (i.e., portrait plus one more) were more diagnostic than the portrait lineup only, Wald χ2(1, N = 138) = 5.91, p < .05. Furthermore, all three lineups were more diagnostic than the portrait only, Wald χ2(1, N = 64) = 11.40, p < .001, and the portrait plus one more lineup, Wald χ2(1, N = 160) = 6.21, p < .05.
More specifically, the odds of identifying a guilty suspect rather than an innocent suspect were about 29 times larger when combining all three lineups, compared to using the portrait lineup only. The odds of identifying a guilty suspect and not an innocent suspect were about six times larger when combining all three lineups than when using the portrait lineup plus only one other lineup. Note that the observed effects were actually even stronger. However, zero (0) values that occurred in any cell had to be replaced with one (1) values in order to be able to run GEE analyses (see Table 7). This lends clear evidence to the notion that combining lineups substantially increases the odds of identifying a guilty suspect over the odds of identifying an innocent suspect, in comparison to a portrait lineup by itself or a portrait plus one other lineup.
Lineup rejections
For lineup rejections, none of the three comparisons resulted in any significant effects. This result reflects the inconclusive result pattern found for multiple rejections (see Table 6).
Foil choices
There was no significant effect for the comparison between two lineups and portrait lineups only, Wald χ2(1, N = 50) = 0.00, ns. However, three lineups were more diagnostic than the portrait lineup plus one other lineup, Wald χ2(1, N = 92) = 3.98, p < .05, but not significantly more diagnostic than the portrait lineup by itself, Wald χ2(1, N = 58) = 0.83, ns. Indeed, Table 6 shows that the results for combinations of two lineups were very mixed for foil choices.
Don't know answers
For don't know answers, none of the three comparisons resulted in any significant effects.
Any non-target/suspect decision outcomes
To establish the diagnosticity of non-suspect choices, an analysis for all cases in which no suspect was chosen in the portrait lineup (i.e., combining rejections, foil choices, and don't know answers) was run. The model including only the main effects produced a common odds ratio of 9.02. This means that choosing a suspect from the portrait lineup was much more likely when the suspect was guilty (148 of 192) than when the suspect was innocent (57 of 192), Wald χ2(1, N = 192) = 77.94, p < .001. Note that the OR represents the unbiased estimate of the common odds ratio, computed as the exponent of the regression coefficient of presence of target (= 2.199). Taking the exponential of this number gives the common odds ratio of 9.02.
For this analysis, the interaction also reached significance, Wald χ2(1, N = 192) = 25.69, p < .001, indicating that the odds ratio for the victim (OR = 41.8) was larger than the odds ratio for the thief (OR = 2.9).
This means that the effect was much stronger for the victim than for the suspect. It is possible that this had to do with specific features of two victim targets. Indeed, identification accuracies for the victims were high (73.6 and 83.3%), compared to those of the thieves (43.8 and 53.4%). Another explanation could be that attention varied as a function of target role (victim vs. thief).
Discussion
The aim of the present study was twofold. On the one hand, it investigated the incriminating value of suspect choices. On the other hand, it examined the exonerating value of lineup rejections, foil choices, and don't know answers. Note that specific significance tests for the comparisons were computed of the probative value of a portrait lineup only vs. a portrait lineup plus one, and plus two additional lineups to establish the beneficial value of these lineups in addition to the standard portrait lineup.
Compared to lineup rejections, foil choices and don't know answers, target/suspect choices were most diagnostic, as expected. This is consistent with previous research on face lineups only across a large number of studies analyzed by Clark et al. (2008). For target/suspect choices, the use of three different lineup modes was significantly more beneficial than the use of portrait lineups alone or the use of two different lineup types. Specifically, a wrongful identification of a suspect was 29 times more likely when using a portrait lineup alone, compared to all three lineups. Furthermore, a wrongful identification of a suspect was six times more likely when using two rather than three lineups. Note that the convergence of results from studies conducted in a field setting (Sauerland & Sporer, 2008) and those obtained in laboratory settings (Pryke et al., 2004; the present study) speaks to the validity of laboratory simulations.
Lineup rejections showed some capability of establishing innocence, but not to the same extent as target/suspect choices established guilt. The magnitudes of the obtained conditional probabilities were actually very close to those reported in an earlier study (Sauerland & Sporer, 2008). Nevertheless, the beneficial value of multiple rejections could not be established as no significant differences were found when comparing the probative value of the portrait lineup alone and its combinations with one or two other lineups.
Similarly to the results for lineup rejections, multiple foil choices showed some capability of establishing innocence, but only for very particular combinations. The most successful combination across targets was portrait and body. Overall, the use of three lineups was found to be more beneficial than two, whereas no significant difference was found when comparing the use of three lineups with the portrait lineup only. Thus, the beneficial value of multiple foil choices, compared to individual ones, could not be established.
The current study extends our knowledge about multiple lineups by establishing the probative value of multiple don't know answers. The highest probative value was observed for the combination of profile and body lineups (see Table 6). For the other combinations, there was large variation in the results, depending on the target. This could be a function of the distinctiveness of the targets or their role (thief vs. victim). Multiple don't know decisions were often more diagnostic than multiple rejections. This challenges the view that don't know answers are simply indicators of a weak memory and concurrent unwillingness to choose (Clark et al., 2008). Rather, the present results suggest that don't know answers are given by witnesses who don't recognize the target in the lineups but who are unwilling to make a factual rejection.
To understand these results it might be helpful to take a look at the underlying decision processes. Decisions made by choosers and nonchoosers possess asymmetric features (Sauerland & Sporer, 2009; Weber & Brewer, 2004). Specifically, choosers seem to experience a match between their memory for the target and one of several faces shown in a lineup whereas nonchoosers experience a failure of such a match (Sauerland, Sagana, & Sporer, 2011). Possibly, this absence of a match leads to uncertainty in some witnesses, followed by a reluctance to arrive at a definitive decision. According to the present data, this response behavior does not necessarily speak for a weak memory trace. Still, shouldn't decisions made by witnesses who are willing to make a rejection be more indicative of innocence than don't know responses? Perhaps, employing a thinking aloud methodology (Ericsson & Simon, 1993) might shed some light on the underlying decision processes although some authors have been rather critical of such introspective approaches (Nisbett & Wilson, 1977).
Taken together, the results regarding foil choices and don't know answers have some important implications for practice. Although there were exceptions, participants all in all were more likely to choose a foil or to give a don't know answer whe n they viewed a lineup in which the target was not present, that is, when the suspect was innocent. Hence, as hypothesized, these behaviors have exonerating value rather than just indicating an unreliable witness (foil selection) or a weak memory trace (don't know answer). After all, foil selections happen roughly in 15 - 22% of real cases (see Behrman & Richards, 2005; Valentine, Pickering, & Darling, 2003; Wright & Skagerberg, 2007), constituting about one third of all choices (Wells, Memon, & Penrod, 2006). Even though there often is no documentation of don't now answers -they may form part of the reported rejection rates - one can speculate that these also form a substantial proportion of eyewitness decisions. Thus, the attribution of diagnostic value to these decision types would be highly desirable and this issue should be addressed in future studies.
Our findings are also consistent with previous research looking at decisions from multiple witnesses compared to multiple decisions from one witness. Specifically, Clark and Wells (2008) computed the diagnostic probability of guilt/innocence when one or two witnesses chose the suspect or rejected the lineup, respectively, in addition to a given witness's suspect choice. The results supported the idea of multiple lineup decisions, with the diagnostic probability of guilt increasing with the addition of suspect choices, but decreasing with the addition of rejections. Foil choices, in addition to a given suspect choice, also had exonerating value when foils were selected according to the target description, not according to similarity to the target.
What do the current findings imply with regard to police practice? One argument that might be brought up against the use of multiple lineups is that fewer witnesses may choose the suspect from multiple lineups than from a portrait lineup alone. However, the difference between witnesses making only a portrait choice vs. choosing the same person again in one or two more lineups was not that large in the current study. Specifically, 49.0% of the participants successfully chose the thief from the TP portrait lineup. Still 42.7% of the participants selected the thief from the portrait lineup and one or two more lineups. This looked even better for the victim: 91.7% of the participants successfully chose the victim from the TP portrait lineup, and 88.5% of the participants selected the victim from the TP portrait lineup and one or two more lineups. This is somewhat inconsistent with Pryke et al. (2004, Experiment 1) who found a difference of 20% (75% vs. 55%) when looking at portrait choices only vs. multiple choices. Regardless, it is clear that multiple identifications provide stronger evidence for a suspect's guilt than portrait identifications alone. Hence, the observed reduction in choices that is observed between portrait choices only vs. multiple choices can be viewed as a means of assessing the probative value of a portrait identification. They do not need to be viewed as necessary in order to allow the portrait choice as admissible evidence (Pryke et al., 2004). Future research should look deeper into the different result patterns that can emerge when using multiple lineups in order to provide the courts with some guidelines of how to deal with the different possible outcomes (Pryke et al., 2004).
One should certainly not postulate for the police to implement multiple lineups in every case in the future. However, there are circumstances under which the use of multiple lineups may be particularly promising. According to the principle of encoding specificity (Tulving & Thomson, 1973), performance is greater when the conditions at learning and testing are congruent, rather than different from each other. This has also been shown for face recognition (Liu & Chaudhuri, 2002). Therefore, the use of different facial poses and different aspects of a person should be particularly beneficial for crimes (1) where a witness only saw the perpetrator from a pose different (e.g., from the side) than the one normally used for lineups (i.e., portrait view), (2) in which one (of several) witnesses saw the perpetrator from different perspectives, and (3) in which different witnesses saw the perpetrator from different perspectives. Furthermore, recent research findings suggest that change of pose might be particularly detrimental for (4) cross-race identifications (Sporer & Horry, 2011). Note that creating multiple lineups does not necessarily constitute much extra work for the police. In some cases, in which the authors were consulted as expert witnesses, the police lineups used consisted of two (or three) different pose facial pictures as well as full body pictures. Here, three independent lineups could easily be created by presenting the photos in separate lineups and by blurring/covering the face from the full body photos.
One important issue when studying multiple lineups is the method for establishing innocent suspect choices. The results obtained using two alternative methods differed with regard to the magnitude of the conditional probabilities, with the averaging method leading to larger values in many cases. However, the general result pattern was not fundamentally affected. This is an appealing finding although previous research reported differences also regarding the general result pattern (Sauerland & Sporer, 2008). Researchers and policy makers must be aware of these possible effects of one or the other method and it is recommendable that both measures are reported routinely.
To conclude, the present study has answered some of the open questions with regard to multiple lineups. Specifically, multiple target/suspect choices have incriminating value whereas multiple rejections, foil choices, and don't know answers can have exonerating value. As the judicial system seeks to protect the innocent from false convictions these findings are of high relevance for policy. With regard to the number of lineup modes combined, it seems that using three (rather than two) lineup modes is favorable for suspect choices. More studies using four lineup modes (cf. Pryke et al., 2004, Experiment 2) should investigate whether a fourth lineup adds even more probative value to the procedure (in a significant way). In contrast, for non-suspect choices (don't know answers, foil choices and rejections), the combination of lineups was far less successful than for suspect choices. Furthermore, the results for non-suspect choices were inconsistent across targets. Unfortunately, the design of the current study does not permit an interpretation of the results as a function of target role (victim vs. thief) or other target features (e.g., distinctiveness, sex, age, etc.). One way to overcome this limitation would be to shoot several versions of the same film with different role allocations.
Finally, despite the present positive results decision makers and researchers are warned to view multiple identifications as what they really are: an addition to the probative value of identification evidence, not a safeguard against false identifications or false rejections. Undoubtedly, there will always be witnesses who correctly identify or reject the suspect from the portrait but not from one or several other lineups. Nonetheless, the increase in probative value due to the multiple lineup procedure will be stronger under the conditions described above. On the other hand, multiple lineup evidence, just as individual lineup evidence, must be viewed in light of the probative value of all evidence, not just eyewitness identifications.
References
1. Behrman, B. W., & Richards, R. E. (2005). Suspect/foil identification in actual crimes and in the laboratory: A reality monitoring analysis. Law and Human Behavior, 29, 279-301. doi: 10.1007/s10979-005-3617-y [ Links ]
2. Brewer, N., Weber, N., Clark, A., & Wells, G. L. (2008). Distinguishing accurate from inaccurate eyewitness identifications with an optional deadline procedure. Psychology, Crime & Law, 14, 397-414. doi: 10.1080/10683160701770229 [ Links ]
3. Brewer, N., & Wells, G. L. (2006). The confidence-accuracy relationship in eyewitness identification: Effects of lineup instructions, foil similarity, and target-absent base rates. Journal of Experimental Psychology: Applied, 12, 11-30. doi: 10.1037/1076-898X.12.1.11 [ Links ]
4. Brown, C., Lloyd-Jones, T. J., & Robinson, M. (2008). Eliciting person descriptions from eyewitnesses: A survey of police perceptions of eyewitness performance and reported use of interview techniques. European Journal of Cognitive Psychology, 20, 529-560. doi: 10.1080/09541440701728474 [ Links ]
5. Clark, S. E. (2005). A re-examination of the effects of biased lineup instructions in eyewitness identification. Law and Human Behavior, 29, 395-424. doi: 10.1037/a0015185 [ Links ]
6. Clark, S. E., Howell, R. T., & Davey, S. L. (2008). Regularities in eyewitness identification. Law and Human Behavior, 32, 187-218. doi: 10.1007/s10979-006-9082-4 [ Links ]
7. Clark, S. E., & Wells, G. L. (2008). On the diagnosticity of multiple-witness identifications. Law and Human Behavior, 32, 406-422. doi: 10.1007/s10979-007-9115-7 [ Links ]
8. Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Hillsdale, NJ: Lawrence Erlbaum Associates. [ Links ]
9. Cooper, H., Hedges, L. V., & Valentine, J. C. (Eds.). (2009). The handbook of research synthesis and meta-analysis. New York, NY: Sage. [ Links ]
10. Ericsson, K. A., & Simon, H. A. (1993). Protocol analysis: Verbal reports as data. Cambridge, MA: MIT Press. [ Links ]
11. Fleiss, J. L., Levin, B., & Paik, M. C. (2003). Statistical methods for rates and proportions. New York, NY: Wiley. [ Links ]
12. Hanley, J. A., Negassa, A., Edwardes, M. D., & Forrester, J. E. (2003). Statistical analysis of correlated data using generalized estimating equations: An orientation. American Journal of Epidemiology, 157, 364-375. doi: 10.1093/aje/kwf215 [ Links ]
13. Lindsay, R. C. L., Wallbridge, H., & Drennan, D. (1987). Do the clothes make the man? An exploration of the effect of lineup attire on eyewitness identification accuracy. Canadian Journal of Behavioural Science, 19, 464-478. doi: 10.1037/h0079998 [ Links ]
14. Lipsey, M. W., & Wilson, D. B. (2001). Practical meta-analysis. Thousand Oaks, CA: Sage. [ Links ]
15. Liu, C. H., & Chaudhuri, A. (2002). Reassessing the three-quarter view effect in face recognition. Cognition, 83, 31-48. doi: 10.1016/S0010-0277(01 )00164-0 [ Links ]
16. Meissner, C. A., Sporer, S. L., & Schooler, J. W. (2007). Person descriptions as eyewitness evidence. In R. C. L. Lindsay, D. F. Ross, J. D. Read, & M. P. Toglia (Eds.), Handbook of eyewitness psychology: Vol. 2: Memory for people (pp. 3 -34). Mahwah, NJ: Lawrence Erlbaum Associates. [ Links ]
17. Nisbett, R. E., & Wilson, T. D. (1977). Telling more than we can know: Verbal reports on mental processes. Psychological Review, 84, 231-259. doi: 10.1186/17417007-4-8 [ Links ]
18. Pozzulo, J. D., Dempsey, J. L., & Gascoigne, E. (2009). Eyewitness accuracy when making multiple identifications using the elimination line-up. Psychiatry, Psychology and Law, 16(Suppl. 1), S101-S111. doi: 10.1080/13218710802456025 [ Links ]
19. Pryke, S., Lindsay, R. C. L., Dysart, J. E., & Dupuis, P. (2004). Multiple independent identification decisions: A method of calibrating eyewitness identifications. Journal of Applied Psychology, 89, 73-84. doi: 10.1037/0021-9010.89.1.73 [ Links ]
20. Sauerland, M., Sagana, A., & Sporer, S. L. (2011). Postdicting nonchoosers' eyewitness identification accuracy from photographic showups by using confidence and response times. Law and Human Behavior. Advance online publication. doi: 10.1037/h0093926 [ Links ]
21. Sauerland, M., & Sporer, S. L. (2008). The application of multiple lineups in a field study. Psychology, Crime & Law, 14, 549-564. doi: 10.1080/10683160801972519 [ Links ]
22. Sauerland, M., & Sporer, S. L. (2009). Fast and confident: Postdicting eyewitness identification accuracy in a field study. Journal of Experimental Psychology: Applied, 15, 46-62. doi: 10.1037/a0014560 [ Links ]
23. Sporer, S. L., & Cohn, L. D. (2011). Meta-analysis. In B. Rosenberg & S. D. Penrod (Eds.), Research methods in forensic psychology (pp. 43-62). New York, NY: Wiley. [ Links ]
24. Sporer, S. L., & Horry, R. (2011). Pictorial versus structural representations of ingroup and outgroup faces. Journal of Cognitive Psychology, 23, 974-984. doi: 10.1080/20445911.2011.594434 [ Links ] 25. Steblay, N., Dysart, J., & Wells, G. L. (2011). Seventy-two tests of the sequential lineup superiority effect: A meta-analysis and policy discussion. Psychology, Public Policy, and Law, 17, 99-139. doi: 10.1037/a0021650 [ Links ] 26. Tulving, E., & Thomson, D. M. (1973). Encoding specificity and retrieval processes in episodic memory. PsychologicalReview, 80, 352-373. doi: 10.1037/h0020071 [ Links ] 27. Valentine, T., Pickering, A., & Darling, S. (2003). Characteristics of eyewitness identification that predict the outcome of real lineups. Applied Cognitive Psychology, 17, 969-993. doi: 10.1002/acp.939 [ Links ] 28. Weber, N., & Brewer, N. (2004). Confidence-accuracy calibration in absolute and relative face recognition judgments. Journal of Experimental Psychology: Applied, 10, 156-172. doi: 10.1037/1076-898X.10.3.156 [ Links ] 29. Wells, G. L. (1978). Applied eyewitness testimony research: System variables and estimator variables. Journal of Personality and Social Psychology, 36, 1546-1557. doi: 10.1037/0022-3514.36.12.1546 [ Links ] 30. Wells, G. L., Charman, S. D., & Olson, E. A. (2005). Building face composites can harm lineup identification performance. Journal of Experimental Psychology: Applied, 11, 147-156. doi: 10.1037/1076-898X.11.3.147 [ Links ] 31. Wells, G. L., & Olson, E. A. (2002). Eyewitness identification: Information gain from incriminating and exonerating behaviors. Journal of Experimental Psychology: Applied, 8, 155-167. doi: 10.1037/1076-898X.8.3.155 [ Links ] 32. Wells, G. L., Memon, A., & Penrod, S. D. (2006). Eyewitness evidence: Improving its probative value. Pychological Science in the Public Interest, 7, 45-75. doi: 10.1111/U 529-1006.2006.00027.x [ Links ] 33. Wells, G. L., Rydell, S. M., & Seelau, E. P. (1993). The selection of distractors for eyewitness lineups. Journal of Applied Psychology, 78, 835-844. doi: 10.1037/0021-9010.78.5.835 [ Links ] 34. Wright, D. B., & Skagerberg, E. M. (2007). Post-identification feedback affects real eyewitnesses. Psychological Science, 18, 172-178. doi: 10.1111/j. 1467-9280.2007.01868.x [ Links ] Received: 25 April 2012 ![]() Correspondence:
Correspondence:
Melanie Sauerland,
Section Forensic Psychology,
Department of Clinical Psychological Science,
Maastricht University, P.O.Box 616,
6200 MD Maastricht, The Netherlands.
Email: melanie.sauerland@maastichtuniversity.nl
Revised: 27 September 2012
Accepted: 1 October 2012

